
Why Memgraph Infrastructure Was Moved to Hetzner
Infrastructure decisions age.
What made sense a few years ago doesn’t always make sense today. Hardware evolves. Workloads change. Costs compound. And sometimes you realize you’re solving problems you no longer need to have.
At Memgraph, we recently made a significant shift:
We moved from running our own co-located hardware infrastructure to running primarily on Hetzner.
This wasn’t just about cost. It was about predictability, benchmarking rigor, and operational simplicity. Here’s what changed and why.
1. From Owning Hardware To Renting the Right Abstractions
For years, we ran our own machines in a datacenter. We owned the hardware and paid for:
- Rack space
- Power
- Bandwidth
- Maintenance
On paper, that looked efficient. In practice, it meant we were also responsible for:
- Hardware refresh cycles
- Failing disks and fans
- Networking issues
- Manual repairs
- On-site interventions
Over time, those responsibilities added up.
After moving to Hetzner, our infrastructure costs dropped by roughly 50% compared to our previous datacenter setup*, for a comparable footprint. All this without owning a single physical server.
*Note: This was before the latest price increase, but it’s still not far off that number.
2. Splitting Workloads by Purpose
We don’t use a single type of machine for everything. Instead, we intentionally split workloads:
- Hetzner shared vCPU instances (Hetzner Cloud) power CI and builds.
- Hetzner bare metal servers (Hetzner Robot, auction machines) are used exclusively for benchmarking
Because builds and benchmarking optimize for very different goals.
Hetzner Shared vCPU for Builds: Optimized for Velocity
For CI and release builds, what matters most is:
- Speed
- Parallelization
- Cost efficiency
After migrating to shared vCPU instances in Hetzner Cloud, we saw a significant improvement compared to our old hardware. For example, our release build and test times dropped from 13.3 minutes (±5.5 minutes) to 8.6 minutes (±1.9 minutes). That’s roughly a 35% reduction in average build time.
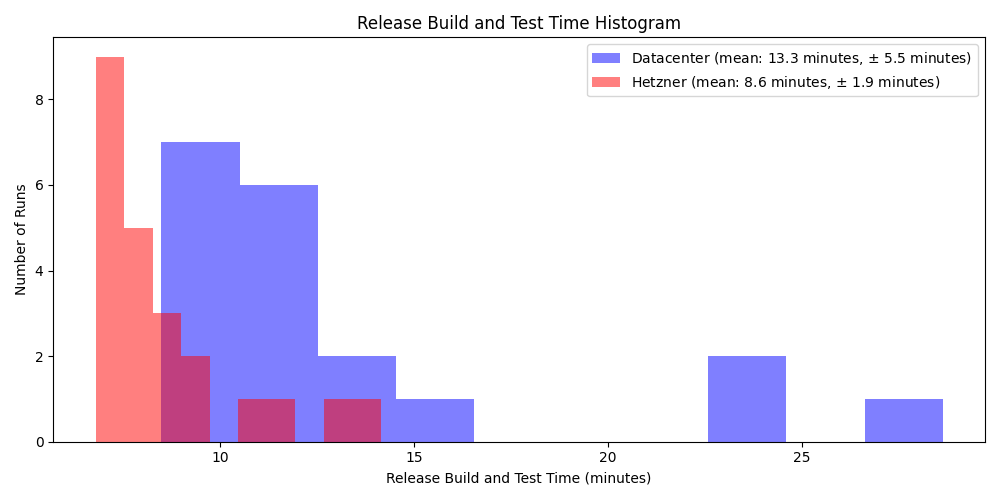
Just as important was the reduction in variability. The old co-located datacenter machines had a wide spread of build times, with occasional slow runs caused by aging hardware or networking instability. On Hetzner’s shared vCPU instances, build times became more consistent, with fewer outliers and a tighter distribution around the mean.
Faster and more predictable builds directly improve developer feedback cycles and reduce the turnaround time for testing new features and fixes.
Hetzner Bare Metal for Benchmarking: Optimized for Determinism
Benchmarking is different. As a database company, performance stability matters as much as raw speed. If infrastructure introduces noise, it becomes difficult to detect small regressions or validate optimizations.
We compared four environments:
- Old, co-located hardware
- Hetzner shared vCPU (Hetzner Cloud)
- Hetzner Dedicated vCPU
- Hetzner Bare metal (Hetzner Robot)
When we normalized results and examined variance, the trend was clear.
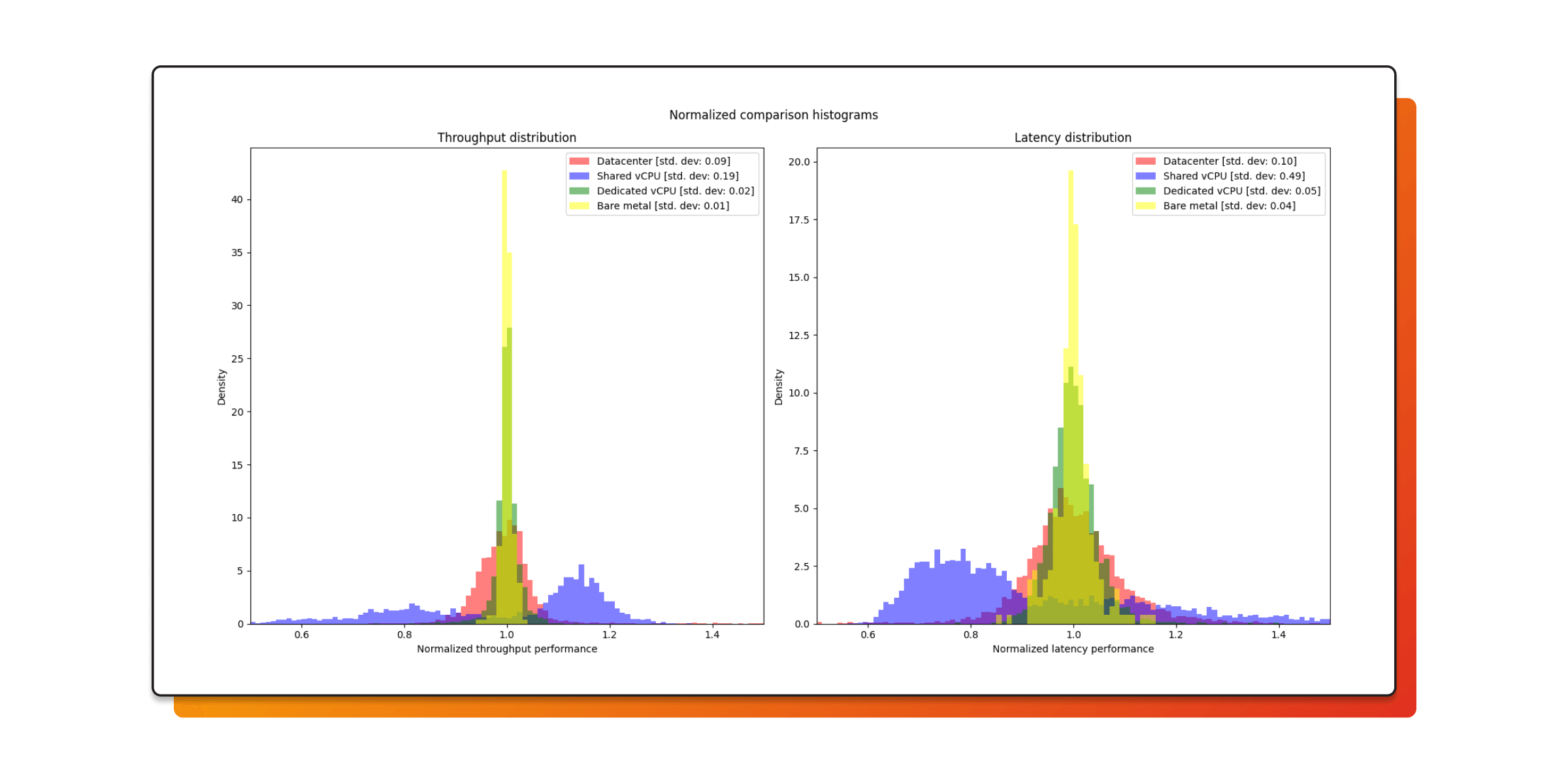
| Hardware |
Throughput Variability (Standard Deviation) |
Latency Variability (Standard Deviation) |
|---|---|---|
| Old, co-located hardware | 0.09 | 0.10 |
| Hetzner shared vCPU | 0.19 | 0.49 |
| Hetzner dedicated vCPU | 0.02 | 0.05 |
| Hetzner Robot (bare metal) | 0.01 | 0.04 |
Moving from shared infrastructure to bare metal reduced:
- Throughput variance by nearly an order of magnitude
- Latency variance by more than 10×
That’s not a marginal improvement. It’s the difference between noisy measurements and reproducible experiments.
Shared virtual machines are fast and economical, but they introduce scheduling noise and occasional latency spikes. Hetzner dedicated vCPUs remove most of that variability and are surprisingly close to bare metal in stability.
With Hetzner bare metal, we went further: we pinned CPU frequencies and confined benchmark threads to cores within individual NUMA nodes, eliminating nearly all remaining variance.
For benchmarking, that determinism is transformative. Our confidence in the results is higher than ever before. We can reliably detect small performance changes and trust that improvements are real and regressions actionable, rather than artifacts of noisy infrastructure.
In short:
Hetzner shared vCPU is optimized for cost-efficient velocity. Hetzner bare metal is optimized for scientific rigor.
3. Reliability: The Quiet Improvement
Our old co-located hardware had recurring friction:
- Flaky networking
- Aging hardware
- Failing disks and fans
- Slow support response times
- Manual intervention when something broke
None of these issues were catastrophic; but collectively, they created instability in CI and benchmarking.
CI failures caused by infrastructure issues were common. Engineers often had to rerun builds and tests multiple times before they succeeded, slowing down development and reducing confidence in results.
After migrating to Hetzner, we saw:
- Faster and considerably more stable networking
- Newer hardware
- Faster storage
- Automatic maintenance
- 24/7 monitoring
- Faster support responses
However, no infrastructure is perfect. Outages still occur, but they are typically localized to a specific rack or datacenter. The blast radius is small, and most of our CI continues uninterrupted.
Operationally, the biggest change is what we no longer do:
- No more hardware lifecycle planning
- No more emergency disk replacements
- No more on-site coordination
- No more acting as our own datacenter operators
We shifted our focus back to building the database.
Wrapping Up
Our move to Hetzner was driven by a desire for faster and more reliable infrastructure, and it truly delivered on that promise:
- Our CI pipelines are faster and more stable.
- Our benchmarking is more rigorous and reproducible.
- Our infrastructure costs are significantly lower than our previous co-located datacenter setup.
- And our engineering team can focus on building features instead of maintaining hardware.
The biggest improvement wasn’t just performance. It was clarity in our results, in our processes, and in how we allocate engineering time.