
How to Replace Kubernetes kubectl Debugging with a Graph
Kubernetes rarely gets hard because you cannot inspect a single object. It gets hard when one question turns into six lookups across pods, services, ingresses, nodes, and persistent volumes.
Which deployment is serving this hostname? What breaks if this host goes away? Which services are using persistent storage? You can answer those questions with kubectl, bash, and some patience. The problem is that the path from question to answer is usually more procedural than it should be.
In this Memgraph Community Call, Artavazd (Art) Balaian, Senior Lead Software Engineer at Agoda, walked through how he built Ariadne, a live Kubernetes graph engine that turns cluster state into a Memgraph property graph, keeps it fresh with incremental updates, and exposes it to engineers and agents through MCP.
The session covered the architecture behind the system, the graph modeling choices that made Kubernetes queryable in a more natural way, and the validation layer needed to make natural language to Cypher workflows less brittle.
If you missed the live session, check out the full Community Call recording here.
Below are the key takeaways from the session.
Key Takeaway 1: Kubernetes Operations Already Look Like a Graph Problem
A lot of day-to-day Kubernetes work is really graph traversal in disguise.
A ReplicaSet manages pods. Pods run containers. Nodes host pods. Services route to workloads. Ingresses connect public hostnames to service backends.
You can chase those relationships procedurally. That usually means several kubectl calls, custom scripting, and the added work of making sure you did not miss a resource type in the middle.
Art’s point was straightforward. If the problem is naturally relational and multi-hop, model it that way.
That shift matters because it changes the shape of the question. Instead of “which command do I run next,” you can ask for the full path in one query. For instance, this Cypher query resolves an external hostname all the way down to the pods currently backing it, and it ran in 7 ms only.
MATCH
(h:Host)-[:IsClaimedBy]->(:Ingress)
-[:DefinesBackend]->(:IngressServiceBackend)
-[:TargetsService]->(:Service)
-[:Manages]->(:EndpointSlice)
<-[:ListedIn]-(ea:EndpointAddress)
-[:IsAddressOf]->(p:Pod)
RETURN DISTINCT
h.name AS host_name,
p.metadata.namespace AS namespace,
p.metadata.name AS pod_name
ORDER BY host_name, namespace, pod_nameKey Takeaway 2: Converting Kubernetes States into Entities & Edges
Art's project Ariadne takes live Kubernetes state, converts it into entities and edges, and stores it in Memgraph as a property graph. That sounds simple. The hard part is deciding how to keep that structure intact while still making it queryable.
Kubernetes objects are irregular. They are deeply nested. They are full of maps, lists, annotations, and fields that are useful until somebody tries to flatten them into a cleaner but less truthful shape.
Art explicitly avoided that. He wanted:
- a live model of the cluster.
- questions that still feel natural to Kubernetes.
- one interface for humans to query using Cypher and agents to safely interact via MCP.
- no heavy denormalization just to satisfy storage constraints.
That choice also helped on the AI side. LLMs have already seen Kubernetes objects, fields, and naming patterns. Keeping the graph close to that structure gives the model a better chance of reasoning correctly.
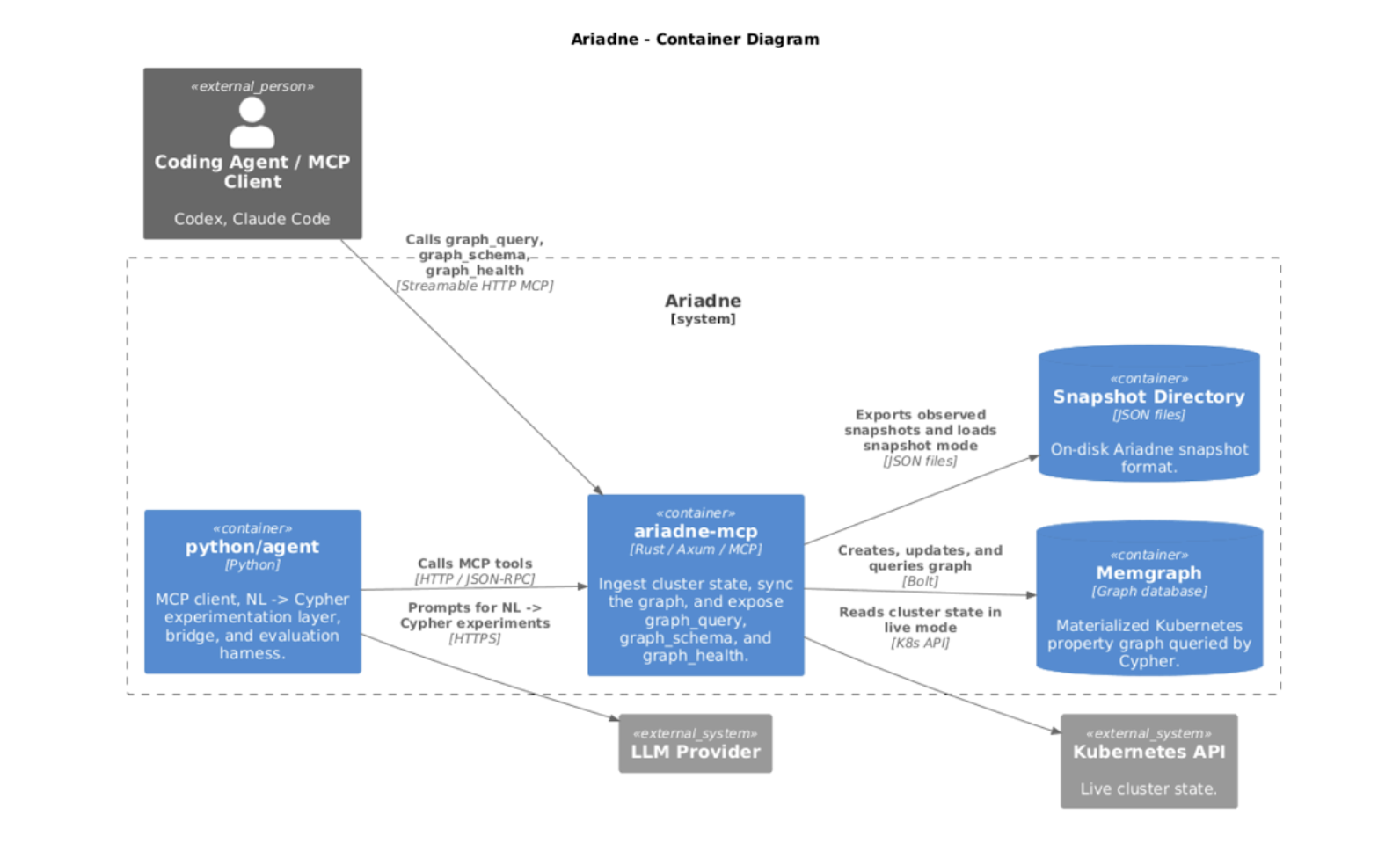
As the architecture flow shows above, Kubernetes API data flows into Ariadne, which builds and updates the graph in Memgraph. The MCP layer then exposes graph_query, graph_schema, and graph_health to agent clients, while Python tooling supports prompt and evaluation experiments.
Key Takeaway 3: Why Memgraph Was a Good Fit
Memgraph fit this use case because Kubernetes data is deeply nested and irregular. Metadata, labels, annotations, specs, and status fields vary a lot across resources, and many objects contain maps inside maps and lists inside lists.
Art did not want to force that into a rigid schema or flatten it into something less useful. Memgraph’s flexible property model let him keep that shape without heavy denormalization while still making it queryable.
That also helped on the AI side. He wanted to stay close to Kubernetes naming and structure because LLMs have already seen those objects and fields during training.
Cypher made the multi-hop operational questions concise and readable, and Memgraph’s native Bolt protocol through rsmgclient gave him direct, low-overhead communication from Rust.
He still kept one boundary for security reasons, such as not reading ConfigMap data contents.
On top of the raw Kubernetes resources, he added logical nodes and relationships so the graph was actually useful to traverse.
Key Takeaway 4: Why Incremental Sync Mattered
A live Kubernetes graph is only useful if it stays reasonably fresh.
Ariadne starts with a full snapshot, then switches to incremental updates through Kubernetes watch events. Instead of re-reading the whole cluster every few seconds, it pulls changed objects and diffs them against in-memory state.
That keeps the graph current without creating unnecessary load. Art shared example numbers from a real cluster with about 3,000 graph nodes, 7,500 edges, and roughly 70 edge types. Initial graph build took nearly six seconds. Typical steady-state diffs took around 30 milliseconds, with freshness lag around 1.1 seconds.
It also avoids hammering the Kubernetes API with repeated full reads just to maintain a live model.
Some logical objects are easier to remove and recreate than track incrementally. Occasional full recomputation is still a useful safety valve when needed.
Key Takeaway 5: MCP Was the Right Boundary for Agent Access
Art decided not to expose the graph database directly to agents. Instead, Ariadne uses MCP as a narrow boundary with three core tools:
graph_queryschemagraph_health
That design gives the model what it actually needs.
It can inspect the graph shape. It can check whether the system is updated and available. It can run allowed queries. It cannot wander around raw database access and improvise its way into confidential territories.
Rather than “giving the model more freedom”, it is important to “give the model better boundaries.”
Key Takeaway 6: Validation is Critical Part of the Workflow
Art spent time experimenting with model quality, evals, intermediate representations, and prompt search. Some of it helped. A lot of it hit the usual wall.
Models still hallucinate. They invent properties. They invent edges. They flip edge directions. They ignore rules you already put in the prompt.
So the real work moved into validation.
Generated Cypher goes through syntax checks and semantic checks before it reaches Memgraph. Queries are restricted to read-only behavior. Edge existence and edge direction are validated against the modeled graph. Response sizes are bounded so the model cannot pull back garbage at token-burning scale.
He also described a specific bad filtering pattern inside MATCH that kept showing up even after explicit prompting. Instead of begging the model to behave, he blocked the pattern and returned feedback it could use to self-correct.
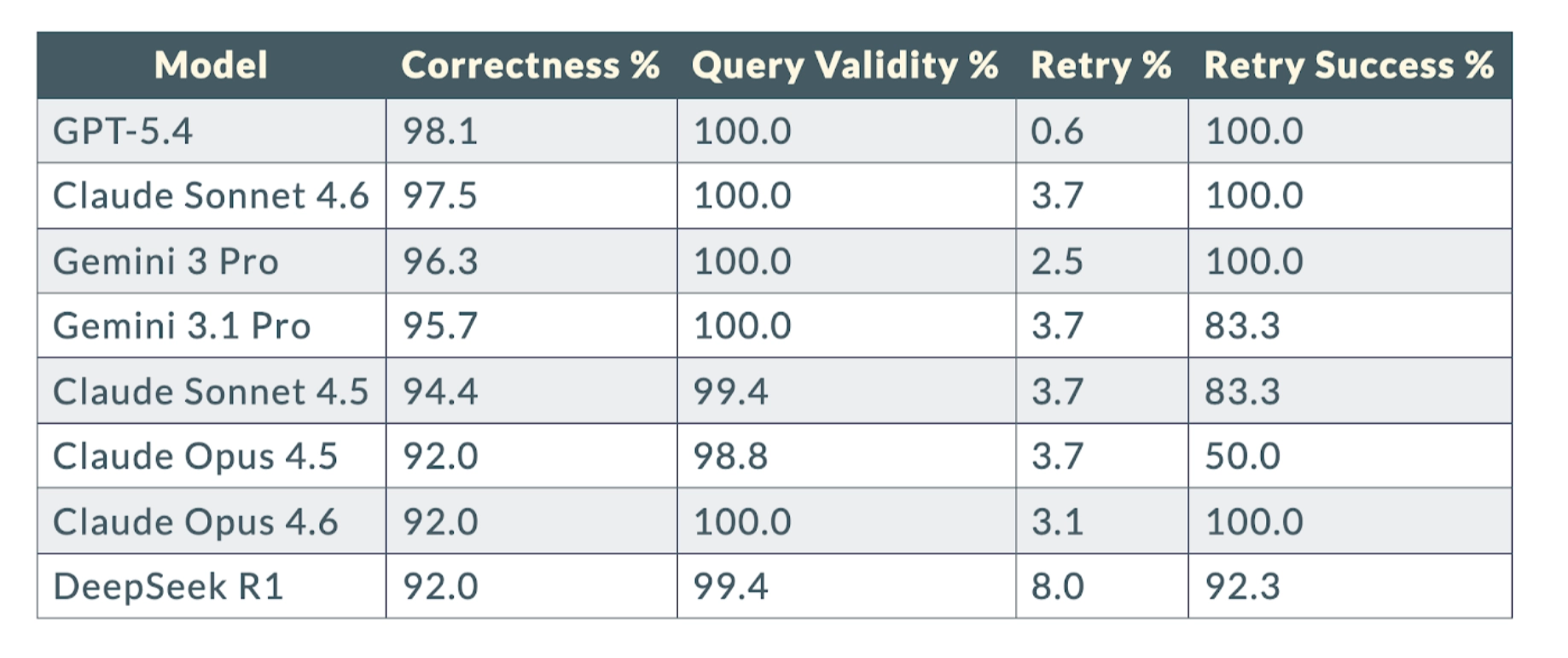
The eval results made that point more concrete. The benchmark covered 12 models across 162 gold questions.
Evaluation Results: Frontier Models
Evaluation Results: Local Models
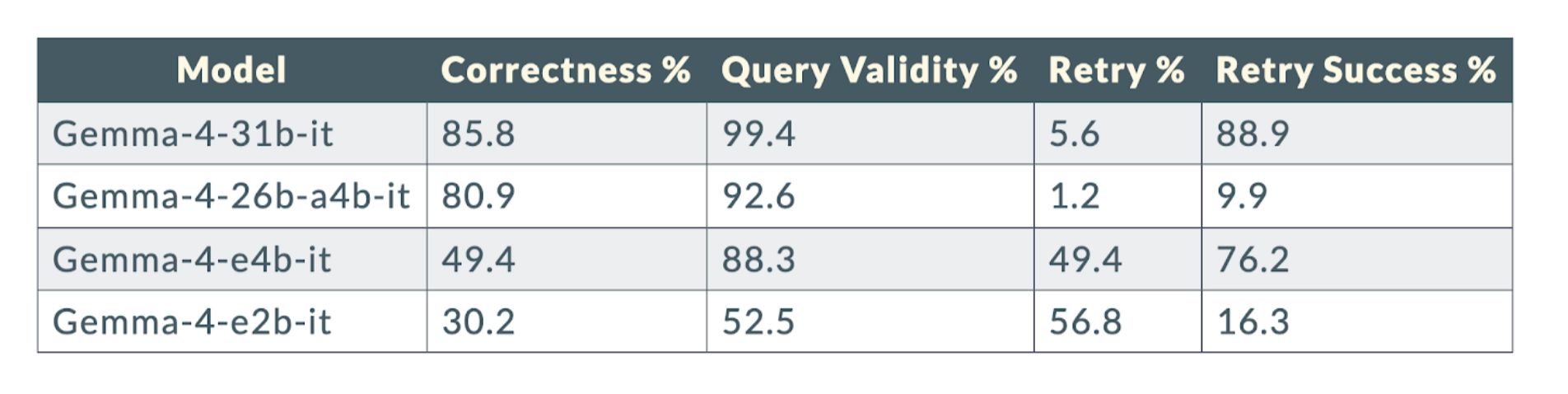
The spread is hard to ignore. Frontier models were consistently strong. Smaller local models dropped off significantly. Hence, interface design and validation choices mattered more than raw model choices.
Key Takeaway 7: The Live Demo Showed the Payoff
The examples focused on questions that are annoying in the usual tooling flow and clean in a graph. Art showed examples of practical, multi-hop questions, such as:
- which deployment serves a specific hostname
- how many pods back it and which nodes they run on
- which public hostnames are impacted if a host is drained
- whether the backing pods for certain services use persistent volumes and which StorageClass they use
The pattern was consistent. The agent checked graph health, asked for schema, reasoned over the graph, and returned a grounded answer.
One result in the demo concluded that draining a given host would reduce capacity rather than cause a full outage. Another traced persistent volume usage and reported LVM as the StorageClass for the relevant services.
Explore the Ariadne repo on GitHub yourself!
Wrapping Up
A live Kubernetes graph becomes useful when an operational question stops being about one object.
It starts to matter when the answer depends on several connected resources. It also becomes more useful when the question is multi-hop, or when both engineers and agents need to query the same system without rebuilding the logic each time.
That is what made Ariadne interesting. It stayed close to Kubernetes, handled live state with incremental updates, and added the boundaries needed to make agent access more reliable.
If you want to go deeper into the architecture, demo, and discussion, watch the full on-demand recording here
Get started with Memgraph to try it first hand!
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
- How do you (efficiently) detect that a certain resource is no longer in your K8s cluster and propagate that information or display that to the end user/agent?
- Ariadne keeps current state in memory, assigns identifiers to modeled objects, and uses Kubernetes watch events plus diffing to classify resources as added, updated, or removed. For some logical objects, remove-and-recreate is simpler than incremental tracking. Periodic full recomputation is still useful to keep drift under control.
- Is the value mainly that this replaces several kubectl commands with one natural-language question?
- That is part of it, but not the whole story. Simple single-object lookups can still be more token-efficient with procedural code. The graph approach becomes more compelling when the question is multi-hop, because it is cheaper in tokens and easier to validate.