
Building a Backend for ODIN and RUNE: How to Make a Knowledge Extraction Engine
I read a Ph.D. thesis a while ago called “Neurosymbolic Machine Learning for Reasoning” by K. Yang. The gist of the thesis is you can have graphs that model something and use machine learning methods on them to get much better results than by just using machine learning methods. The author of the thesis applied machine learning to automated theorem proving since theorems can be modeled by graphs.
Fast-forward a couple of months, Alex and I joined Memgraph as interns. Our job was to make a cool new app, integrating LLMs like OpenAI’s GPT-4 with the Memgraph database. Alex, being a programmer with quite a few personal projects under his belt, thought about making something that would help him navigate his Git repos, understand their structure, and possibly even generate project skeletons for different frameworks like Angular or Spring Boot. I approached it from the angle of the thesis I read, and I wanted to make an intelligent system that could reason on knowledge graphs. The most suitable environment for something like that was Obsidian since I had already been using it and wanted to sort of supercharge it with LLM capabilities. We figured out that we could actually make one project out of our two ideas since a lot of the code and functionality could be shared.
So we started working on a two-part project, one concerned with code and another with notes. The code part evolved into RUNE, and the other into ODIN. We made ODIN and RUNE to be repos in their own right and named the backend BOR (backend for ODIN and RUNE; also, Bor is Odin’s father 😁).
TLDR: The structure of BOR
BOR has an information extraction engine that turns code repositories or Obsidian vaults (notes) into a knowledge graph stored in the blazing-fast, in-memory Memgraph DB. Langchain Agents can query the knowledge graph or a ChromaDB vector store to try to answer your questions about the code repository or your notes. There are also some fun bonus features. See the image in how to make an LLM Agent section for a visual overview of the app.
How to make graphs
For starters, we made something that makes graphs (stored in Memgraph DB) from notes written in natural language. Graphs are isomorphic to an ordered set of Cypher queries, so in reality, we made something that makes Cypher queries from notes written in natural language. Langchain was our library of choice for integrating LLMs into our project. Using Langchain, you can just initialize a ChatOpenAI model, pass it a SystemMessage, which tells it how to behave, and a HumanMessage, which essentially models any external input.
It turns out that an LLM will do anything if you ask it nicely, including generating a set of Cypher queries (CREATE, MERGE, and SET) from natural language text. To avoid any confusion, we made sure that the LLM returns only the Cypher queries, so we made a system message that goes like this:
Your task is to convert natural language into a knowledge graph.
You will be given a prompt in natural language, designated by <prompt>.
The prompt comes from a file, given after <file_path>.
The file is stored in a repository, given after <repo_path>.
Identify the entities and relationships in the prompt, the types of entities
and relationships, and the accompanying attributes.
Convert the prompt into a knowledge graph which consists of Cypher CREATE and MERGE queries after <cypher>.
Pay special attention to the direction of edges.
Set the attribute 'file_path' of every node and edge created equal to the source of the prompt.
Set the attribute 'repo_path' of every node and edge created equal to the repository where the prompt comes from.And a human message going like this:
<prompt>
{prompt}
<repo_path>
{repo_path}
<file_path>
{file_path}
<cypher>And… this works! Well, it works perfectly with GPT-4 and more-or-less awfully with GPT-3.5, but well, check out the mock_cypherls in BOR to get a feeling of the kind of Cypher queries GPT generates.
In addition, we made something that makes graphs from code repositories. First off, the repositories can be local (on your computer), in which case our LocalRepoManager just runs through the filesystem using os.walk and gathers info about each file: what programming language it was written in (check this out to see how it works, we downloaded languages.yml from GitHub’s linguist repo), whether it has a TODO in it, and how many lines of code it has. The repository structure is mirrored in the graph structure.
Secondly, the repositories can be accessed via the GitHub API. In that case, only the repository structure is mirrored in the graph, and the nodes don’t have any additional attributes. This is because we didn’t want to download the whole repository (you can just do it yourself, and then it’s a local repo) or make too many API calls. So, BOR, in this case, serves more as a quick lookup thing for a GitHub repo.
How to make an LLM Agent
Okay, so now we have more or less all of the data we need. We have a nice knowledge graph which contains information about either our notes or our code. See how cool it is to visualize your notes like this!
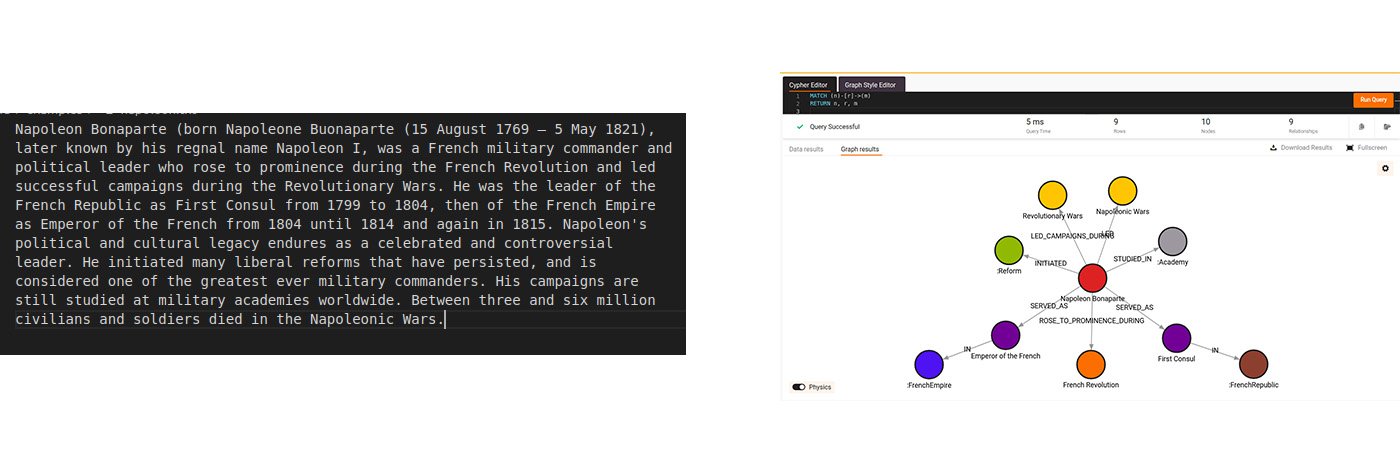
The other most important parts of BOR are the Agents, which can interact with Memgraph DB and other tools as best as they can until they answer your question. We have three of them: The GeneralQueryAgent, the CodeQueryAgent, and the NotesQueryAgent. As you can probably guess, the CodeQueryAgent and NotesQueryAgent are subclasses of the GeneralQueryAgent since, while searching through code and notes, some functionality is duplicated. This is a common theme in this project and the reason why Alex and I wanted to merge our two ideas into one “backend” repo. In line with this, all agents have the same system message, which informs them about the schema currently present in Memgraph with llm_util.schema (thanks, Brett! Go watch Memgraph’s Community call with Brett).
All of the Agents are OpenAI functions agents (AgentType.OPENAI_FUNCTIONS inside Langchain). These Agents are based on special OpenAI models (like gpt-3.5-turbo-0613), which “...have been fine-tuned to detect when a function should be called and respond with the inputs that should be passed to the function. In an API call, you can describe functions and have the model intelligently choose to output a JSON object containing arguments to call those functions.” So if you provide your agent with a list of tools inside initialize_agent and then invoke agent.run(“My question is..”), then the agent will use whatever tools you define to try as best as it can to answer your query.
Let’s make a quick visualization so I can better explain what the Agents interact with. Each arrow connecting an Agent to something that is not an Agent is essentially a tool. ‘w’ means write, ‘r’ means read, and ‘embeddings’ is a tool offering semantic search:
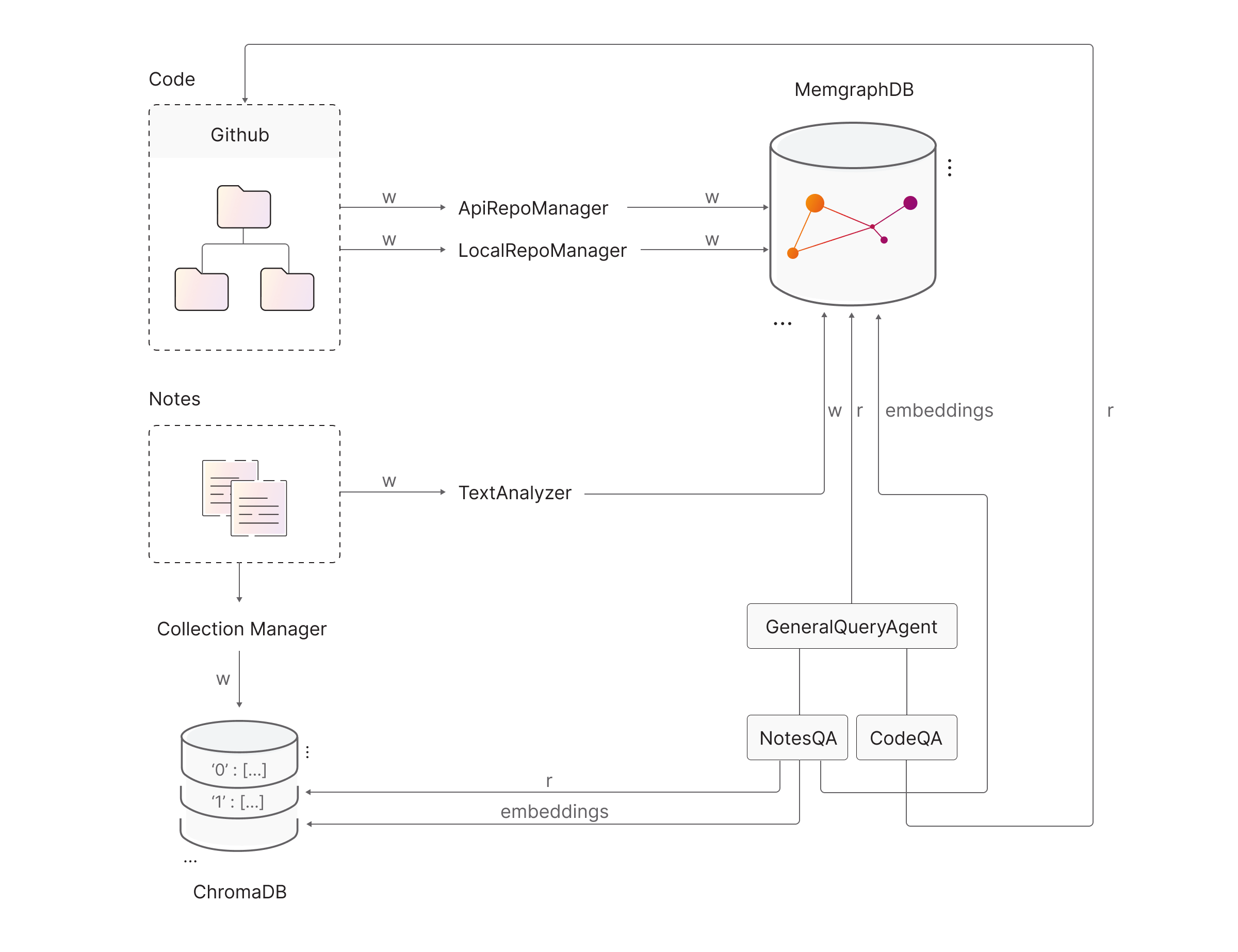
Our GeneralQuery agent can only run a Cypher query on an already-running Memgraph instance. The connection to the instance is handled by gqlalchemy, and the app assumes that Memgraph is available on localhost, port 7867. When first developing the app, we ran everything locally for testing purposes but then dockerized the whole thing. Even though it has only one tool, the ability to run a Cypher query to try to get an answer to a question is really powerful.
The NotesQueryAgent inherits the functionality of the GeneralQuery agent and can additionally semantically search through your notes (using the ChromaDB vector store) and through your knowledge graph (using Memgraph and the node_similarity.cosine_pairwise function present in MAGE). Check out the semantic search engine paragraph to see how we implemented the semantic search.
The CodeQueryAgent is conceptually much simpler than the NotesQueryAgent, since it has two simpler tools available: it can read out the contents of a single file entirely, and it can get an output of the directory tree from a given root directory.
How to make a semantic search engine
If you don’t already know what semantic search really is, I’ll try to explain it in the next two paragraphs; if you do, feel free to skip them.
Computers operate with numbers, right? So neural networks (which run on computers) operate with numbers, too. All of the GPT models understand text, so in the making of a GPT model, there should exist a step that converts text into numbers. And indeed, such a step exists! It turns out that GPTs learn how to represent text (actually, one word at a time) with a huge list of numbers called a vector. The way that they learn is as follows: they look at how all of the words in the whole of the Internet relate to each other (this is handwavy, I know, but check out the Transformer paper if you want to know the details), and see how they should map the words to vectors, such that the most semantically similar words are vectors which have more or less the same direction. Also, check out the following blog post from Katarina to learn more about vector similarity. This is called embedding because you embed text in a vector space. We will always calculate our embeddings using text-ada-002 from OpenAI’s Embeddings API.
The semantic search, thus, comes down to this: if I have a bunch of text, like in a book called Light Bringer, and I can’t remember exactly what I’m looking for but do remember that I want to search for something like “integrity of dawn knight,” I can just search for that and get my favorite quote from the book: “I am Cassius Bellona, son of Tiberius, son of Julia, brother of Darrow, Morning Knight of the Solar Republic, and my honor remains.” Notice that the traditional search would fail to find this since the words don’t match exactly, but they do match in meaning. Under the hood, the semantic search engine has calculated the embedding of my query and found the sentence most similar (the vector closest) to my query.
Now we got that out of the way, let’s talk about our search engine implementation. First of all, semantic search is enabled only for the Notes part of BOR (that is, for ODIN). That’s because people already figured out how to embed natural language but not code, as far as I know.
The notes themselves are fairly easy to semantically search through with the power of ChromaDB (see this vector store tutorial from Langchain). You can think of all vector stores as a giant associative array between chunks of text and their embedding vectors:
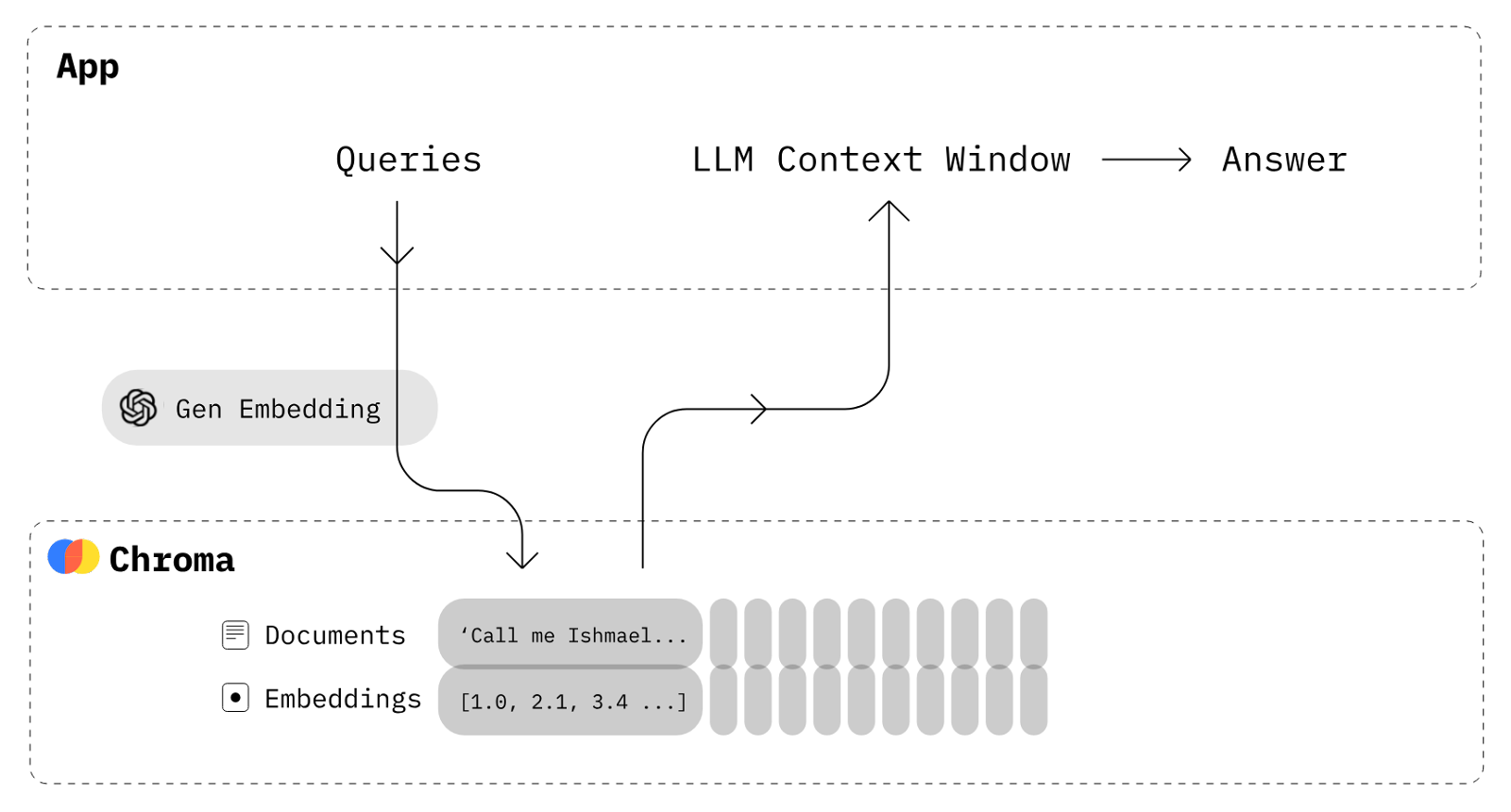
The chunking part is what we did differently in relation to other most common semantic search engines. We wanted to have a 1-to-N correspondence between an Agent’s search query and sentences found in the notes, so we used the sentence tokenizer from the Natural Language Toolkit, which proved to be fast and accurate. In the above image, each “Document” would be a single sentence in our notes (Obsidian Vault).
We also wanted to enable semantic search on nodes so that we could get the most semantically similar nodes to a given search query. To do that, we first formed a string describing each node using its type and relationships to all of its neighboring nodes using this Cypher query and then again used text-ada-002 to calculate the embeddings.
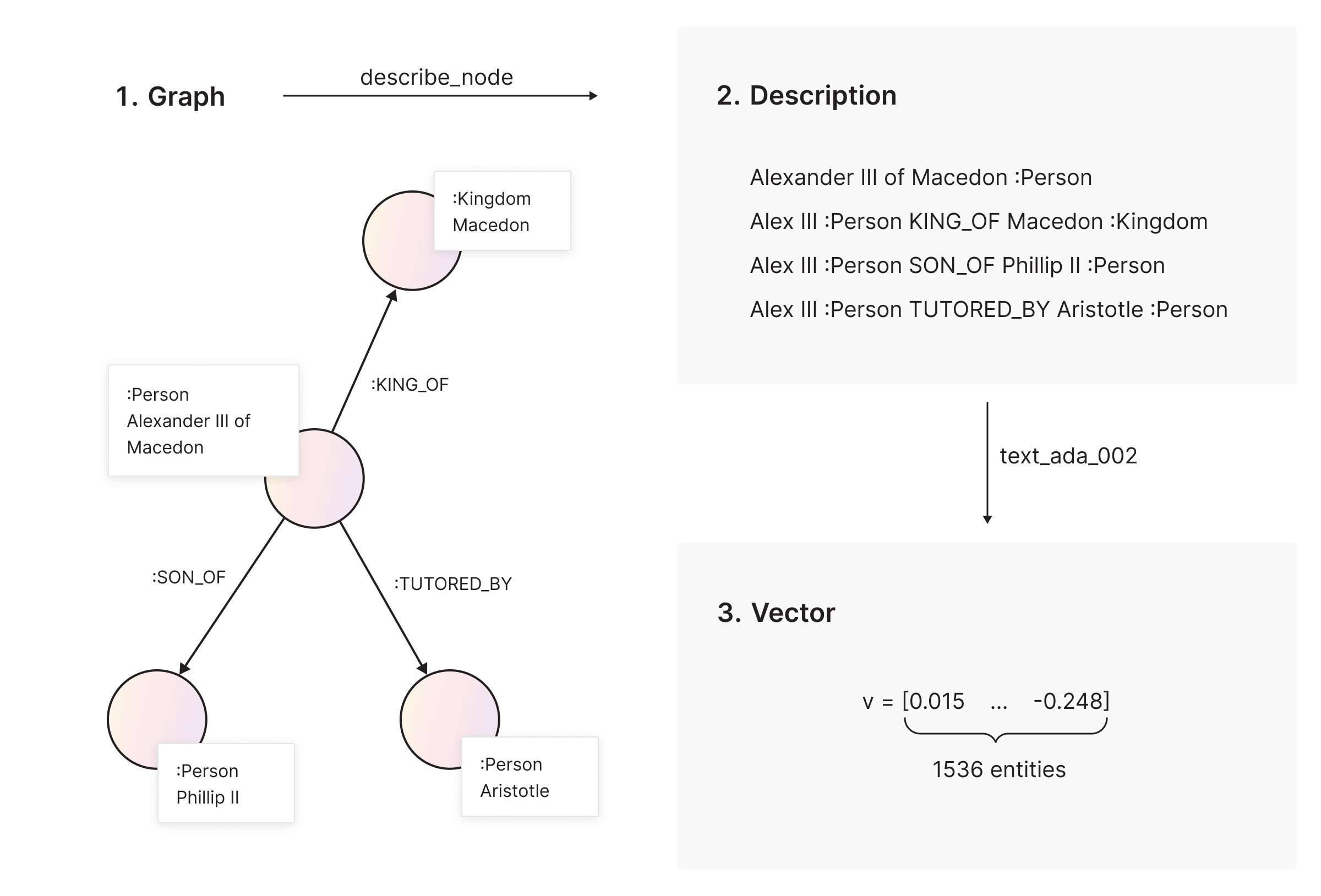
After enriching our graph with the attribute ‘embeddings’ attached to each node, we can search through the nodes and get N (in our case, N=3) most relevant nodes for a given search query, with the node_similarity.cosine_pairwise() function.
Once we finished the semantic search functionality, we got all the tools we needed to pass to our Agents, and our Agents became alive!
How to make a simple REST API
Honestly, this was super straightforward and easy, thanks to the absolutely amazing FastAPI. For each function we wanted to expose to the frontend, we made a separate endpoint. Several data classes were defined to streamline things. The backend docker image spins up both the Memgraph image and itself, so the frontend sends requests only to the backend. Take a look at api.py to see how easy it is to define a REST API using FastAPI (the whole API lives only in this file!)
Bonus features
We decided to implement some bonus features just because we thought it would be fun for us and useful for the user. For ODIN, we made a node_to_sentences and sentence_to_nodes endpoint, which return the 3 most semantically similar nodes to a highlighted sentence and vice versa. The user can click on a node in the right “knowledge graph pane” and get sentences that are associated with that node and vice versa. Both features are super fun. We also implemented a quick criticize-me method, which, given an excerpt from a note, asks GPT to poke holes in what the author of the note said and provide additional research questions about the text. Additionally, we made an automatic Obsidian link suggestion function, which can tell you what note most likely contains something similar to what you are talking about in the current note.
For RUNE, we decided to make endpoints called optimize_style, explain, and debug. They operate on a highlighted code snippet and are really self-explanatory. Since RUNE has the same right knowledge-graph pane as ODIN, the LLM’s responses to those queries are shown there.
La fin
If you’ve read this far, thank you, and congratulations! This was mostly a stream-of-consciousness blog post in which I tried to explain how we made BOR and why we made some decisions regarding the implementation. In general, if you’re making apps that contain LLM functionality or relatively autonomous agents based on an LLM, I would always start with first making an information extraction engine (since you can’t do anything if you don’t have data), then consider what functionality I want my Agents to achieve, and finally make Tools which enable my Agents to reason and do things.
I know that BOR can probably be improved in a lot of ways and that the code is neither optimally performant nor has the best style or is bug-free, so if you want to contribute to BOR, please do! Open an issue, and we can talk.