
Building a BitClout Social Network Visualization App With Memgraph and D3.js
Introduction
BitClout is a new decentralized social network that lets you speculate on (the worth of) people and posts with real money. It's built from the ground up as its own custom blockchain. Its architecture is similar to Bitcoin's, except that it supports complex social network models like posts, profiles, follows, speculation features, and much more at a significantly higher throughput and scale. Like Bitcoin, BitClout is a fully open-source project and there is no company behind it, it's just coins and code.
In this tutorial you'll learn how to develop a simple application for visualizing and analyzing the BitClout social network using Memgraph, Python, and use D3.js. To make things as simple as possible, you are going to use Docker to containerize your application and achieve hassle-free cross-platform development.
Prerequisites
- Memgraph DB: a Streaming Graph Application Platform that helps you wrangle your streaming data, build sophisticated models that you can query in real-time, and develop applications you never thought possible, all built on the power of the graph. Follow the Docker Installation instructions.
- Flask: a web framework that provides you with tools, libraries and technologies used in web development. A Flask application can be as small as a single web page or as complex as a management interface.
- Docker and Compose: an open platform for developing, shipping, and running applications. It enables you to separate your application from your infrastructure (host machine). If you are installing Docker on Windows, Compose will be already included. For Linux and macOS visit this site.
- Python 3: An interpreted high-level general-purpose programming language.
- pymgclient: A Python driver for connecting to Memgraph
You can find the source code in our GitHub repository if you don’t want to work on it as you go through the tutorial. If at any point in this tutorial you have a question or something is not working for you, feel free to post on StackOverflow with the tag memgraphdb. So let's get started!
Scraping the BitClout HODLers Data
To acquire the data from the BitClout website you'll need to scrape the data using a method that renders HTML or ping the BitClout servers directly by using an undocumented API.
The scraping method might be a bit easier since you don't have to worry about headers too much.
That can be done using a browser inside Python like Selenium, and parsing the HTML with beautiful soup.
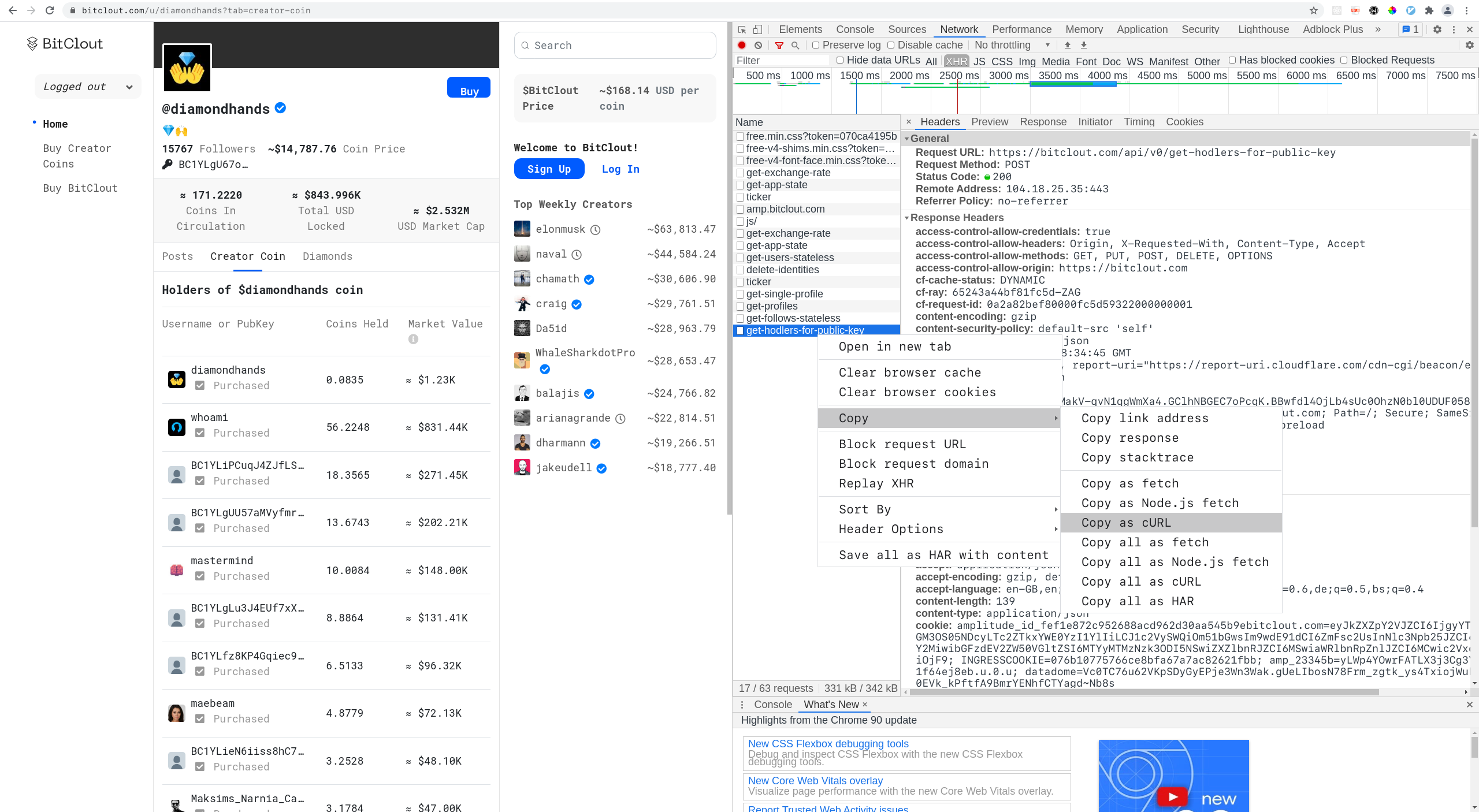
Getting the API to work might be a bit trickier but the upside is; it requires no parsing. You can head over to a BitClout account of a content creator, under the Creator Coin tab, you'll notice a call to the /api/v0/get-hodlers-for-public-key route if inspecting network traffic with a developers console in Chrome.
All that's left is to copy the headers from the console and convert them to a cURL command. Then you can make a post request to BitClout and get the information about each account individually.
Here's the python script.
Creating The Flask Server Backend
Before you begin with any actual coding, you need to decide on the architecture for your web application.
The main purpose of the app is to visualizes the BitClout network so let's create a small Flask server with one view. This will also make your life easier in case you choose to extend the app at some point with additional functionalities or different visualization options.
Let's implement the actual Flask server that will handle everything. Start by creating the file bitclout.py and add the following code to it:
import os
MG_HOST = os.getenv('MG_HOST', '127.0.0.1')
MG_PORT = int(os.getenv('MG_PORT', '7687'))You are going to specify environment variables in the docker-compose.yml file later on and this is how they are retrieved in Python. Next, let's set up some basic logging:
import logging
log = logging.getLogger(__name__)
def init_log():
logging.basicConfig(level=logging.INFO)
log.info("Logging enabled")
logging.getLogger("werkzeug").setLevel(logging.WARNING)
init_log()Nothing special, but this will give you a clear overview of how the app is behaving. In the same fashion, let's define an optional (but often helpful) input argument parser:
from argparse import ArgumentParser
def parse_args():
parser = ArgumentParser(description=__doc__)
parser.add_argument("--app-host", default="0.0.0.0",
help="Host address.")
parser.add_argument("--app-port", default=5000, type=int,
help="App port.")
parser.add_argument("--template-folder", default="public/template",
help="Path to the directory with flask templates.")
parser.add_argument("--static-folder", default="public",
help="Path to the directory with flask static files.")
parser.add_argument("--debug", default=True, action="store_true",
help="Run web server in debug mode.")
parser.add_argument("--load-data", default=False, action='store_true',
help="Load BitClout network into Memgraph.")
print(__doc__)
return parser.parse_args()
args = parse_args()This will enable you to easily change the behavior of the app on startup using arguments. For example, the first time you start your app it's going to be with the --load-data flag because we need to populate the database.
The next step is connecting to Memgraph so you can populate the database and fetch data at some point:
import mgclient
import time
connection_established = False
while(not connection_established):
try:
connection = mgclient.connect(
host=MG_HOST,
port=MG_PORT,
username="",
password="",
sslmode=mgclient.MG_SSLMODE_DISABLE,
lazy=True)
connection_established = True
except:
log.info("Memgraph probably isn't running.")
time.sleep(4)
cursor = connection.cursor()This is a pretty lazy solution for connecting to the database but it works well.
It's time to create your server instance:
from flask import Flask
app = Flask(__name__,
template_folder=args.template_folder,
static_folder=args.static_folder,
static_url_path='')And with this, you can finally create the view functions that will be invoked from the browser via HTTP requests.
One view function is load_all() which fetches all the nodes and relationships from the database, filters out the most important information and returns it in JSON format for visualization. To can the network load at a minimum, you will send a list with every node id (no other information about the nodes) and a list that specifies how they are connected to each other.
import JSON
from flask import Response
@app.route('/load-all', methods=['GET'])
def load_all():
"""Load everything from the database."""
start_time = time.time()
try:
cursor.execute("""MATCH (n)-[r]-(m)
RETURN n, r, m
LIMIT 20000;""")
rows = cursor.fetchall()
except:
log.info("Something went wrong.")
return ('', 204)
links = []
nodes = []
visited = []
for row in rows:
n = row[0]
m = row[2]
if n.id not in visited:
nodes.append({'id': n.id})
visited.append(n.id)
if m.id not in visited:
nodes.append({'id': m.id})
visited.append(m.id)
links.append({'source': n.id, 'target': m.id})
response = {'nodes': nodes, 'links': links}
duration = time.time() - start_time
log.info("Data fetched in: " + str(duration) + " seconds")
return Response(
json.dumps(response),
status=200,
mimetype='application/json')The second view function is index() and it returns the default homepage view, i.e. the /public/templates/index.html file:
from flask import render_template
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')The only thing that's left is to implement and invoke the main() method:
def main():
if args.load_data:
log.info("Loading the data into Memgraph.")
database.load_data(cursor)
app.run(host=args.app_host, port=args.app_port, debug=args.debug)
if __name__ == "__main__":
main()After seeing the database.load_data(cursor) line, you might ask yourself why we haven't implemented the database module yet. If you are interested in how to populate the database with the BitClout network, continue with the next step but otherwise skip it and just copy the contents of database.py from GitHub.
Importing the BitClout Network into Memgraph
The BitClout network data is stored in three separate CSV files which you will use to populate Memgraph.
Create a database.py module and define a single function, load_data(cursor). This function uses the object cursor for submitting queries to the database. Let's start implementing it step by step:
def load_data(cursor):
cursor.execute("""MATCH (n)
DETACH DELETE n;""")
cursor.fetchall()
cursor.execute("""CREATE INDEX ON :User(id);""")
cursor.fetchall()
cursor.execute("""CREATE INDEX ON :User(name);""")
cursor.fetchall()
cursor.execute("""CREATE CONSTRAINT ON (user:User)
ASSERT user.id IS UNIQUE;""")
cursor.fetchall()The first query deletes everything from the database in case there was some unexpected data in it.
After each query execution comes a cursor.fetchall() invocation which we need to commit database transactions.
The second and third queries create a database index for faster processing.
The fourth query creates a constraint because each user needs to have a unique id property.
The query for creating nodes from CSV files looks like this:
cursor.execute("""LOAD CSV FROM '/usr/lib/memgraph/import-data/profiles-1.csv'
WITH header AS row
CREATE (sample:User {id: row.id})
SET sample += {
name: row.name,
description: row.description,
image: row.image,
isHidden: row.isHidden,
isReserved: row.isReserved,
isVerified: row.isVerified,
coinPrice: row.coinPrice,
creatorBasisPoints: row.creatorBasisPoints,
lockedNanos: row.lockedNanos,
nanosInCirculation: row.nanosInCirculation,
watermarkNanos: row.watermarkNanos
};""")
cursor.fetchall()However, this isn't enough to load all the nodes for the network. Because GitHub has a file size limitation, the nodes are split between two CSV files, profiles-1.csv and profiles-2.csv. Just copy/paste this code segment with one slight adjustment, change the line '/usr/lib/memgraph/import-data/profiles-1.csv' to '/usr/lib/memgraph/import-data/profiles-2.csv'.
The relationships can be created by running:
cursor.execute("""LOAD CSV FROM '/usr/lib/memgraph/import-data/hodls.csv'
WITH header AS row
MATCH (hodler:User {id: row.from})
MATCH (creator:User {id: row.to})
CREATE (hodler)-[:HODLS {amount: row.nanos}]->(creator);""")
cursor.fetchall()Building Your Frontend with D3.js
Let's face it, you are probably here because you want to check out if D3.js is worth considering for this kind of visualization or how easy it is to learn. That's also why I am not going to waste your time by going through the HTML file. Just create a index.html file in the directory public/templates/ and copy its contents from here. The only noteworthy line is:
<canvas width="800" height="600" style="border: ..."></canvas>This line is important because before you begin with anything else, first you need to answer the question: Should I use canvas or svg?. The answer is, as is often the case, it depends on the situation.
This StackOverflow post gives a pretty good overview of the two technologies. I short, canvas is a bit harder to master and interact with, while svg is more intuitive and simplistic when it comes to modeling interactions. On the other hand, canvas is better in terms of performance and is probably best suited for large datasets like our own. We can also use a combination of the two. In this post, we are visualizing the whole network, but if you wanted to visualize only a smaller subset, you could create a separate view with an svg element.
Create the public/js/index.js file and add the following code:
const width = 800;
const height = 600;
var links;
var nodes;
var simulation;
var transform;These are just some global variables that will be needed throughout the script. Now, let's select the canvas element and get its context:
var canvas = d3.select("canvas");
var context = canvas.node().getContext("2d");The next step is to define an HTTP request to retrieve the data from the server:
var xmlhttp = new XMLHttpRequest();
xmlhttp.open("GET", "/load-all", true);
xmlhttp.setRequestHeader("Content-type", "application/json; charset=utf-8");The most crucial part is fetching the data and visualizing it. You will accomplish this inside the EventHandler onreadystatechange() when the server responds with requested JSON data:
xmlhttp.onreadystatechange = function () {
if (xmlhttp.readyState == 4 && xmlhttp.status == "200") {
data = JSON.parse(xmlhttp.responseText);
links = data.links;
nodes = data.nodes;
simulation = d3
.forceSimulation()
.force("center", d3.forceCenter(width / 2, height / 2))
.force("x", d3.forceX(width / 2).strength(0.1))
.force("y", d3.forceY(height / 2).strength(0.1))
.force("charge", d3.forceManyBody().strength(-50))
.force(
"link",
d3
.forceLink()
.strength(1)
.id(function (d) {
return d.id;
})
)
.alphaTarget(0)
.alphaDecay(0.05);
transform = d3.zoomIdentity;
d3.select(context.canvas)
.call(
d3
.drag()
.subject(dragsubject)
.on("start", dragstarted)
.on("drag", dragged)
.on("end", dragended)
)
.call(
d3
.zoom()
.scaleExtent([1 / 10, 8])
.on("zoom", zoomed)
);
simulation.nodes(nodes).on("tick", simulationUpdate);
simulation.force("link").links(links);
}
};Here you parse the JSON response data and separate it into two lists, nodes and links. The forceSimulation() method is responsible for arranging our network and the positions of individual nodes. You can learn more about it here.
You also need to map specific functions with events like dragging and zooming.
Now, let's implement these missing functions. The function simulationUpdate() is responsible for redrawing the canvas when changes are made to an element's position:
function simulationUpdate() {
context.save();
context.clearRect(0, 0, width, height);
context.translate(transform.x, transform.y);
context.scale(transform.k, transform.k);
links.forEach(function (d) {
context.beginPath();
context.moveTo(d.source.x, d.source.y);
context.lineTo(d.target.x, d.target.y);
context.stroke();
});
nodes.forEach(function (d, i) {
context.beginPath();
context.arc(d.x, d.y, radius, 0, 2 * Math.PI, true);
context.fillStyle = "#FFA500";
context.fill();
});
context.restore();
}The dragstart event is fired when the user starts dragging an element or text selection:
function dragstarted(event) {
if (!event.active) simulation.alphaTarget(0.3).restart();
event.subject.fx = transform.invertX(event.x);
event.subject.fy = transform.invertY(event.y);
}The dragged event is fired periodically as an element is being dragged by the user:
function dragged(event) {
event.subject.fx = transform.invertX(event.x);
event.subject.fy = transform.invertY(event.y);
}The dragended event is fired when a drag operation is being ended:
function dragended(event) {
if (!event.active) simulation.alphaTarget(0);
event.subject.fx = null;
event.subject.fy = null;
}That's it for the frontend!
Setting up your Docker Environment
The only thing left to do is to Dockerize your application. Start by creating a docker-compose.yml file in the root directory:
version: "3"
services:
memgraph:
image: "memgraph/memgraph:latest"
user: root
volumes:
- ./memgraph/entrypoint:/usr/lib/memgraph/entrypoint
- ./memgraph/import-data:/usr/lib/memgraph/import-data
- ./memgraph/mg_lib:/var/lib/memgraph
- ./memgraph/mg_log:/var/log/memgraph
- ./memgraph/mg_etc:/etc/memgraph
ports:
- "7687:7687"
bitclout:
build: .
volumes:
- .:/app
ports:
- "5000:5000"
environment:
MG_HOST: memgraph
MG_PORT: 7687
depends_on:
- memgraph
As you can see from the docker-compose.yml file, there are two separate services. One is memgraph and the other is the web application, bitclout. You also need to add a Dockerfile to the root directory. This file will specify how the bitclout image should be built.
FROM python:3.8
# Install CMake
RUN apt-get update && /
apt-get --yes install cmake
# Install mgclient
RUN apt-get install -y git cmake make gcc g++ libssl-dev && /
git clone https://github.com/memgraph/mgclient.git /mgclient && /
cd mgclient && /
git checkout dd5dcaaed5d7c8b275fbfd5d2ecbfc5006fa5826 && /
mkdir build && /
cd build && /
cmake .. && /
make && /
make install
# Install packages
COPY requirements.txt ./
RUN pip3 install -r requirements.txt
# Copy the source code to the container
COPY public /app/public
COPY bitclout.py /app/bitclout.py
COPY database.py /app/database.py
WORKDIR /app
ENV FLASK_ENV=development
ENV LC_ALL=C.UTF-8
ENV LANG=C.UTF-8
ENTRYPOINT ["python3", "bitclout.py", "--load-data"]
The command RUN pip3 install -r requirements.txt installs all the necessary Python requirements. There are only two dependencies in the requirements.txt file:
Flask==1.1.2
pymgclient==1.0.0
Launching your Application
The app can be started by running the following commands from the root directory:
docker-compose build
docker-compose up
If you encounter errors about permissions, just add sudo to the commands.
The first time you run the container, leave everything as it is. Afterward, you don't have to load the BitClout data into Memgraph from CSV files anymore because Docker volumes are used to persist the data. You can turn off the automatic CSV loading by changing the last line in ./Dockerfile to:
ENTRYPOINT ["python3", "bitclout.py"]This is essentially the same as running the server without the --load-data flag.
Conclusion
In this tutorial, you learned how to build a BitClout visualization app with Memgraph, Python, and D3.js. From here you can do a few things:
- If you have any questions, comments or suggestions, make sure to drop us a line on our Discord server.
- If you would like to build your own visualization app, you can download Memgraph here.
- If you want to read other similar tutorials, check out this flight network analysis tutorial, or this fraud detection tutorial.
If you end up building something of your own with Memgraph and D3.js, make sure to share your project with us, and we'll be happy to share it with the Memgraph community!