
RAG vs GraphRAG: Shared Goal & Key Differences
Retrieval-augmented generation (RAG) changed how large language models (LLMs) access information by allowing them to pull in external knowledge through semantic retrieval before generating a response.
GraphRAG builds on this idea by adding structure and reasoning, enabling models to understand how pieces of information are related.
But how do these two approaches differ, and when should you use one over the other? Let’s unpack the differences, not just in design but also in what they enable. If your task is mostly about retrieving the right document, RAG may be enough. If it depends on understanding how entities, events, or systems connect, GraphRAG becomes far more useful.
The Shared Goal: Giving LLMs Real Context
Both RAG and GraphRAG emerged to solve the same problem: LLMs lack up-to-date, connected knowledge.
They generate responses based on patterns learned during training, not on current or domain-specific data.
RAG bridges that gap by retrieving relevant information from external sources such as documents, FAQs, or databases and injecting it into the model’s prompt. It helps the model “look up” the right facts before answering.
GraphRAG takes this one step further. Instead of retrieving standalone chunks of text, it retrieves connected context that shows not only what is relevant but also how those pieces relate to one another.
Key Differences at a Glance
| RAG | GraphRAG | |
|---|---|---|
| Core Concept | Semantic retrieval via vector similarity | Retrieval (semantic, text, or hybrid) plus Graph Reasoning |
| Data Structure | Vector index (flat) | Knowledge graph (nodes and relationships) |
| Context Type | Isolated chunks | Connected, relational context |
| Strengths | - Quick setup - Handles unstructured text | - Multi-hop reasoning - Relationship awareness - Flexible retrieval - Dynamic context updates |
| Limitations | - Lacks reasoning - Over-retrieval - Static context | - Requires graph construction - Slight learning curve for non-graph users |
| Ideal Use Cases | - FAQ bots - Document Q&A - Customer support | - Supply chain analysis - Research graphs - Healthcare intelligence |
RAG: Retrieval Built on Similarity
RAG works by transforming both data and queries into vector embeddings, which are numerical representations that capture meaning.
These vectors live in a vector database, which allows the system to find text that is semantically similar to the query.
When you ask a question, RAG retrieves the top matches, adds them to the model’s context, and generates an answer that feels grounded in external knowledge.
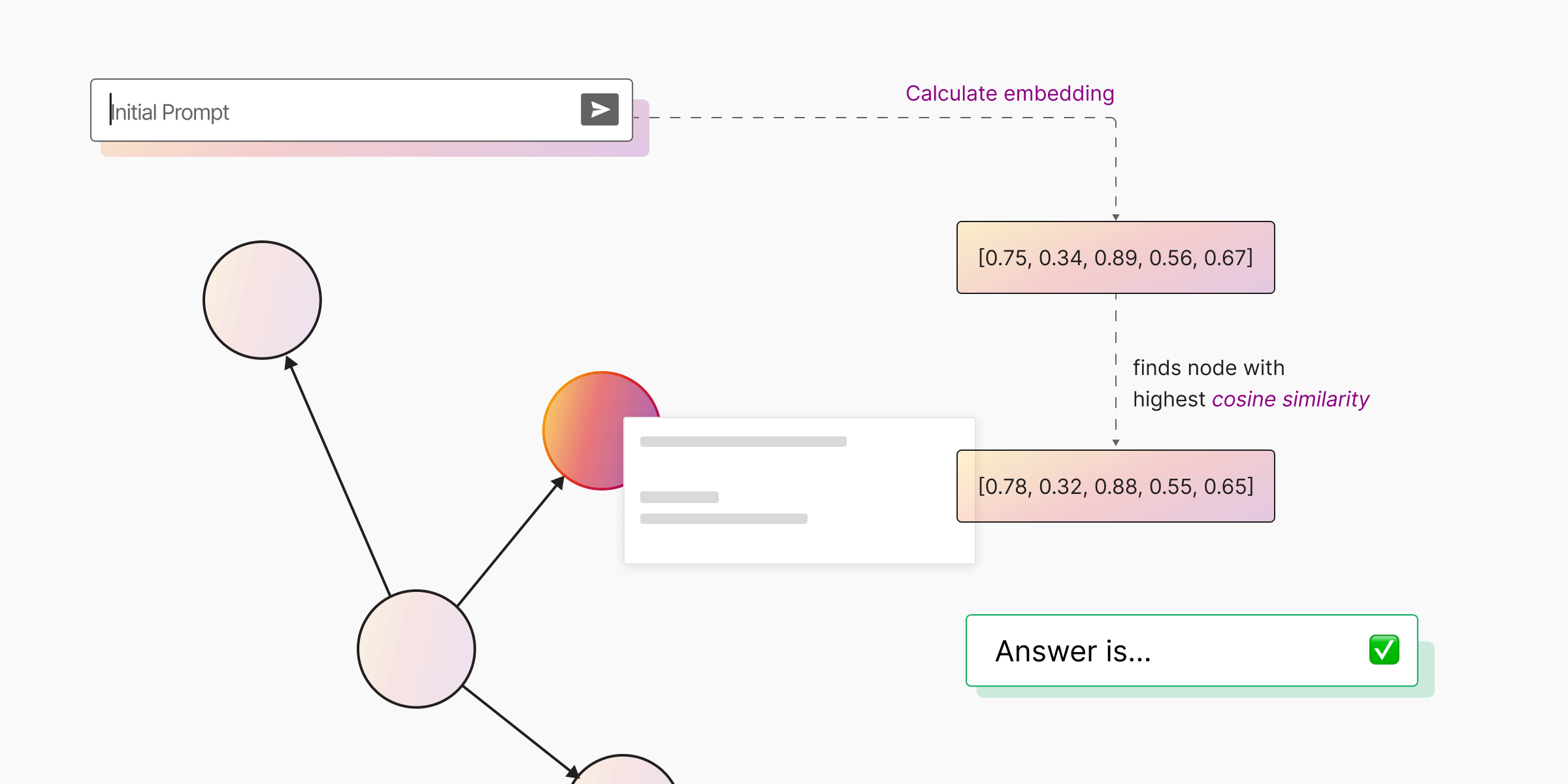
This makes it ideal for scenarios like:
- Customer support assistants that summarize documentation.
- Chatbots that need access to company data.
- Enterprise search across internal documents.
In short, RAG is about semantic similarity, finding what sounds relevant. But it often stops there.
Where RAG Falls Short
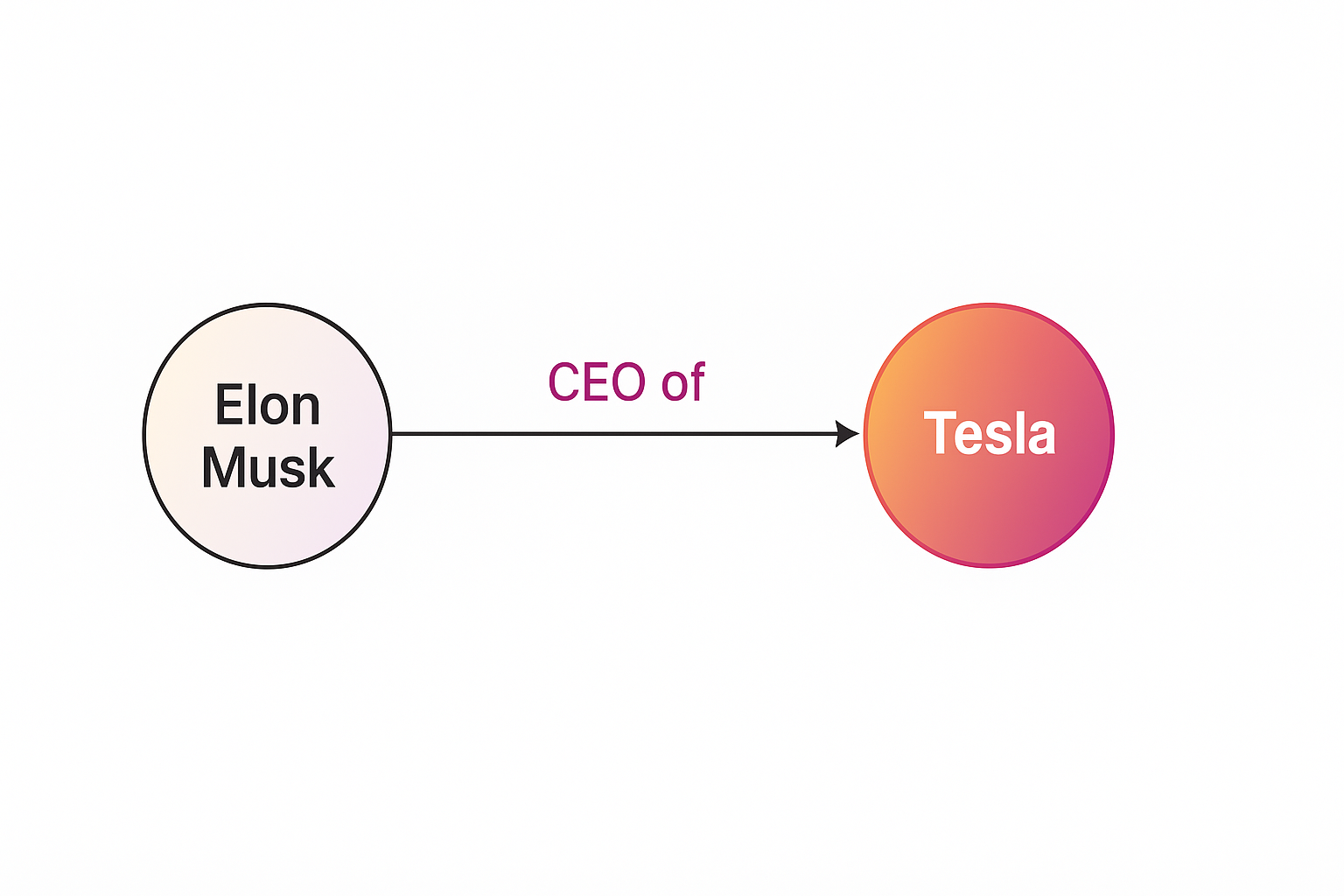
RAG does not inherently understand relationships. It can tell that “Elon Musk” and “Tesla” often appear together, but it can’t reason about how they’re connected, for example, that Elon Musk → CEO of → Tesla.
This leads to common issues:
- Fragmented context: Chunking text breaks logical flow.
- Over-retrieval: Similar but irrelevant snippets may appear.
- No reasoning: It cannot infer connections across multiple facts.
As tasks grow more complex, such as multi-step queries, causality chains, or relational reasoning, RAG struggles to connect the dots.
Read more: What is RAG? Why It Matters & Where It Falls Short
GraphRAG: Retrieval That Understands Relationships
GraphRAG adds a missing layer, structure. It represents information as a knowledge graph of entities and relationships. Instead of storing documents as flat text, it organizes them as nodes (concepts) and edges (relationships), like below.
When a query arrives, GraphRAG does more than search for semantic matches. It identifies key nodes, then traverses the graph to uncover related information through a process called relevance expansion. This gives LLMs context that is both meaningful and connected.
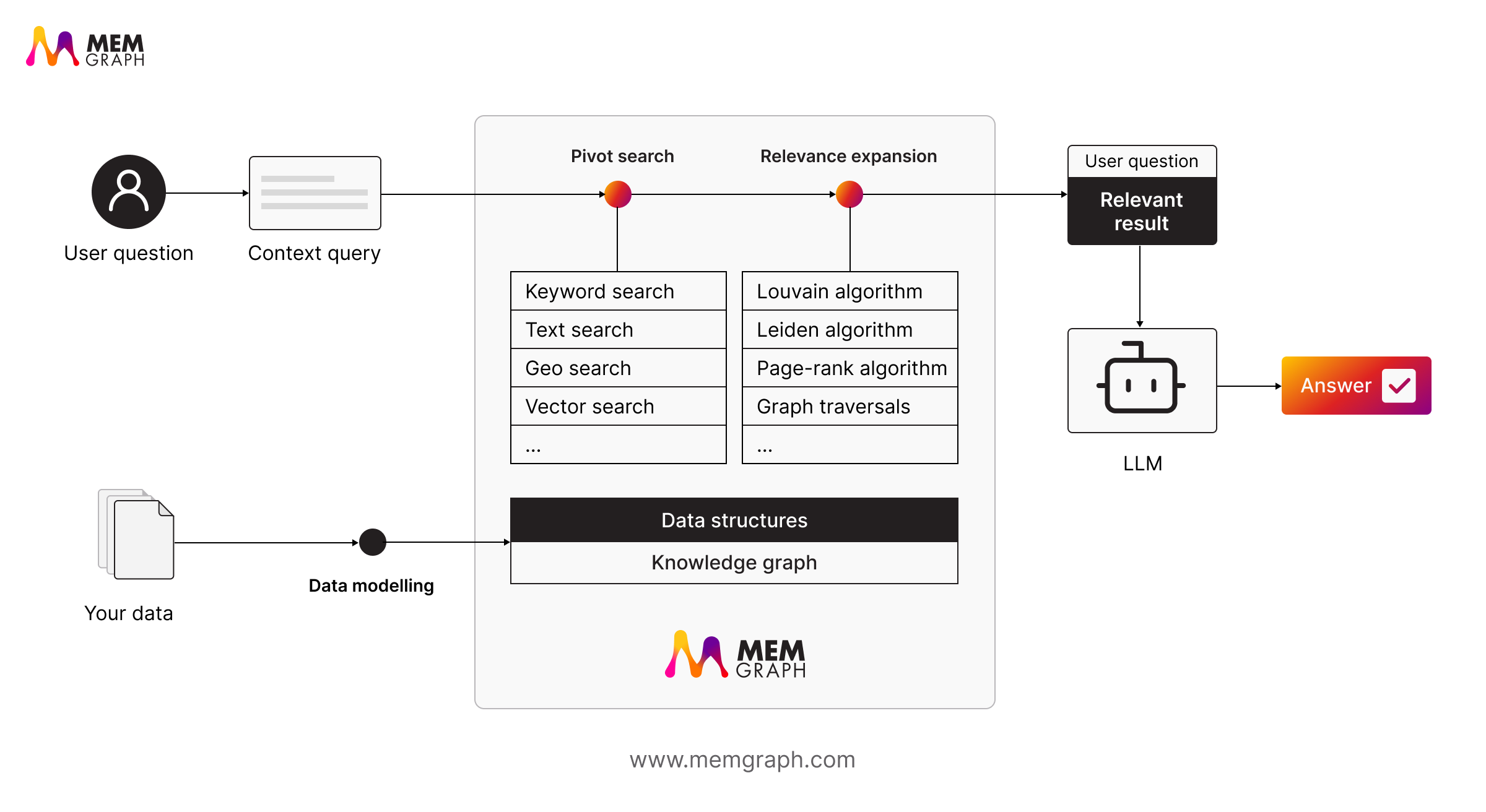
Unlike traditional RAG, GraphRAG’s retrieval layer is flexible. It can use semantic search, keyword or text search, geospatial filters, or hybrid methods to locate relevant entry points (pivots) before expanding context through graph reasoning. The retrieval method simply determines where the reasoning begins.
For example, if you ask, “Which suppliers impact delivery delays?”, GraphRAG can trace paths through a supply chain graph to find all linked entities such as suppliers, shipments, and bottlenecks, even if those terms never appear together in text.
Read more: What Is GraphRAG? A Guide to Connected Context
Why GraphRAG Is Not a Replacement But an Evolution
RAG and GraphRAG are not competitors; they are layers of the same ecosystem. GraphRAG builds on RAG’s foundation of retrieval and extends it into reasoning. It adds structure without sacrificing flexibility.
That is why some systems combine both, like Memgraph. Vector search finds semantically relevant entry points, and graph reasoning explores how they connect. This flexible approach blends the speed of RAG with the intelligence of GraphRAG.
Choosing the Right Approach
The simplest way to choose is to match the retrieval layer to the shape of the question you need to answer:
- Start with RAG when your data is mostly unstructured text and you need quick retrieval for question answering or summarization.
- Move to GraphRAG when relationships matter and you need your system to reason across entities, track dependencies, or evolve with new information.
- Combine both when semantic retrieval is the fastest way to find relevant starting points, but the final answer still depends on traversing relationships across people, systems, events, or documents.
As enterprises push toward AI systems that understand not just facts but how those facts fit together, GraphRAG offers a roadmap for what comes next.
Wrapping Up
Both RAG and GraphRAG exist to make LLMs smarter about the world beyond their training data. RAG gives them access to information, while GraphRAG gives them understanding.
RAG answers questions with the right data. GraphRAG answers them with the right context.
For a deeper look at how each works, check out our earlier explainers:
As data becomes more interconnected, retrieval alone is not enough. The future of AI depends on reasoning through relationships, and that is exactly where GraphRAG shines.