
From RAG to Graphs: How Cognee is Building Self-Improving AI Memory
AI systems today are impressive. However, let’s be honest, they forget almost everything.
Ask a large language model a follow‑up question and it acts like you’ve never spoken before. That’s not memory, that’s mimicry. And if you’re building production‑grade systems, mimicry won’t cut it.
This was the challenge explored in our latest Memgraph Community Call with Vasilije Markovic, founder of Cognee.
The session walked through Cognee’s journey: why current retrieval systems fall short, how a graph‑powered memory layer works, and how this approach is making AI assistants far more reliable.
If you couldnʼt join live, donʼt worry. You can catch the full recording here. Below are some of the highlights from the talk to give you a sense of what was covered.
Key Takeaway 1: Introducing Cognee
Cognee is introduced as a memory system for AI agents. It ships as a Python SDK and is already finding traction across open‑source projects.
Large language models behave like interns with short‑term memory loss. They respond once but fail to recall the same conversation later. Cognee solves this by providing persistent, adaptive memory that carries context forward.
Early adoption shows momentum:
- ~1,000 library downloads
- ~7,000 GitHub stars (or more)
- ~200–300 projects using Cognee (based on telemetry)
These early adoption figures highlight the momentum behind Cognee.
Key Takeaway 2: The Problem with Current RAG Systems
The talk then moved into the limits of RAG. Reliability is the critical issue. Retrieval‑augmented generation fails in around 40% of cases. This figure is no where near the 95%+ reliability expected in production.
RAG pipelines look straightforward:
- Load data in batches (e.g., PDFs, HTML pages, databases).
- Ingest and chunk the data
- Store data in a vector store (e.g., Pinecone, popular at the time).
- Convert data into embeddings (numeric representations).
- At query time, perform vector search to retrieve semantically similar chunks.
- Provide retrieved chunks to the LLM for answer generation.
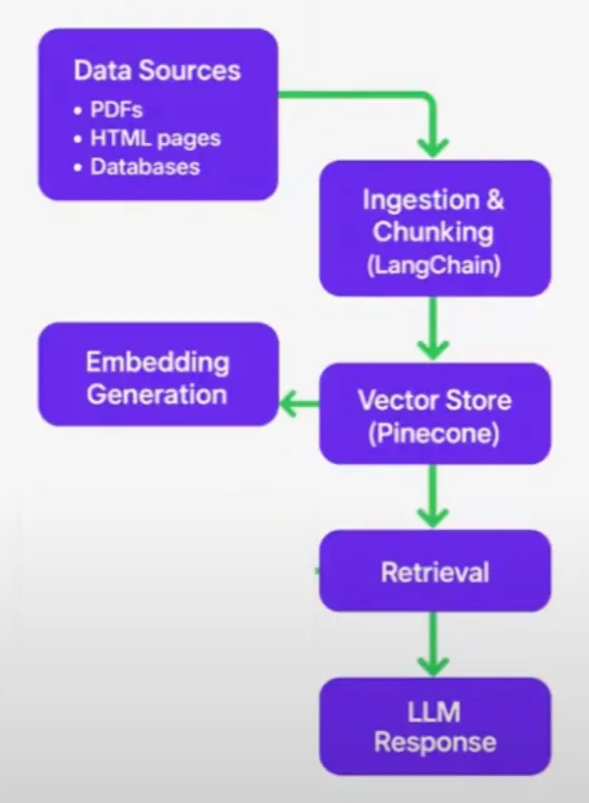
In practice, this pipeline falls apart, facing some critical problems:
- Semantic mismatches are common. A query for a “sports car” when looking for Porsche Taycan might also return ”Model X Sport Refresh” which is an incorrect category.
- Operational pain is constant too as re‑indexing can take days and is prone to breaking. Even modest datasets can overwhelm the setup.
- System faced bottlenecks as it couldn’t handle updates well. Even, basic ACID-style database guarantees were missing resulting in it failing to scale despite relatively small datasets (e.g., 50 MB could already cause issues).
The conclusion was clear: RAG can demonstrate ideas, but it cannot support production workloads alone. This motivated the need for a better approach leading to Cognee’s memory system.
Key Takeaway 3: From RAG to Cognee’s Memory Layer
To overcome RAG’s limitations, Cognee introduced a memory-first architecture. It combining embeddings with graph-based extraction (triplets → subject-relation-object) that were stored in a knowledge graph.
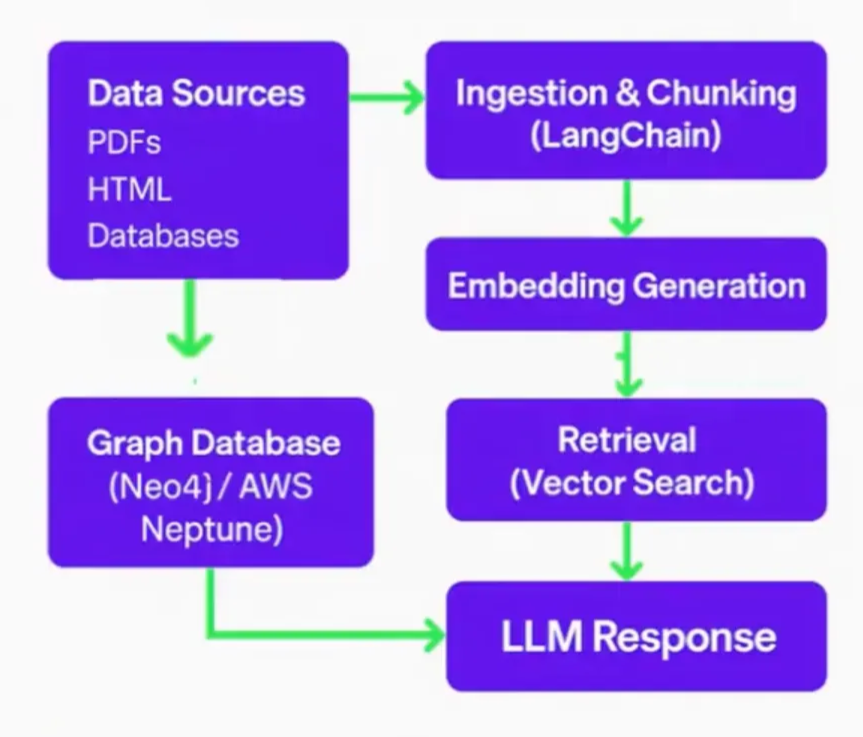
This allowed entities to be represented with granular, context-rich connections, rather than flat vector similarities.The improvement is significant:
- Recall that is context‑aware
- Accuracy approaching 90% compared to RAG’s 60%
- Responses that are solid enough for decision‑making rather than guesswork.
Key Takeaway 4: First Iteration and Early Learnings
The first public SDK proved the idea worked, but it also showed where improvements were needed.
Entity connections gave clearer answers and stronger context. But the system wasn’t parallelized, making performance slow. Updates were fragile, and customization was limited. The early iteration validated the vision but also exposed the work required to reach production quality.
Key Takeaway 5: Expanding Beyond RAG with Memory Features
To move closer to a production system, new features were layered on top of the graph approach:
- Ontologies: captured domain rules, such as credit card interest rates that vary by state.
- RDF loading and state representation: made it possible to store memory locally or in the cloud.
- Composable pipelines: allowed developers to link together parsing, scraping, and search tasks without being tied to rigid flows.
- Reasoning layer: enabled natural language queries, hiding the complexity of Cypher.
- Evaluation framework: stress‑tested the system with thousands of questions to quantify gains.
Each addition helped turn Cognee from a prototype into a tool that can be adapted for real‑world deployments.
Key Takeaway 6: Current System Architecture
The current architecture integrates vectors, graphs, and reasoning into a unified developer‑friendly stack.
The pipeline flows from ingestion across 30+ supported sources, to enrichment with embeddings and graph “memify” steps, and finally to retrieval combining time filters, graph traversal, and vector similarity.
At present, performance sits at around 1 GB processed in 40 minutes using 100+ containers. The latest release is v0.3, with v1.0 on the horizon. Strengths include modular pipelines, serverless‑ready design, user isolation, and versioning. Gaps remain in API usability, lack of a mobile SDK, incomplete TypeScript support, and scaling to terabyte‑sized datasets.
Key Takeaway 7: Demo in Action
Cognee’s Python SDK is designed to balance simplicity with flexibility. Commands like cognify add for ingestion and cognify search for retrieval work out-of-the-box.
The system supports text, files, and datasets, with soft isolation through “notesets.” Ingested data is automatically stored as graph-enriched chunks that can be visualized and queried directly.

This makes entity relationships, such as AI in finance, MedTech growth, or fraud detection, easy to explore.
The platform also includes custom memory algorithms ("Memphis") that clean unused data, reconnect nodes, and improve structure. Developers can extend beyond default setups by building custom pipelines, chaining tasks together for specialized needs.
Deployment options are equally flexible. A full Cognee UI can run locally with a simple cognee ui command, or developers can sync to the cloud with one command and an API key. Adding custom data, creating notebooks, and using copilot-style tutorials for code and data representation are all supported.
Overall, Cognee emphasizes a developer-first experience that is quick to start with defaults, yet extensible for advanced pipelines and adaptable for both local and cloud environments.
Wrapping Up
Without memory, AI will stay stuck in repetition. Cognee demonstrates a way forward by combining graphs, ontologies, and reasoning layers to deliver assistants that can actually remember.
This recap only covers the highlights. For the full walkthrough, watch the recording here.
Future Memgraph Community Calls will continue to dig into the practical lessons that make graph‑powered AI systems work in the real world.
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
- How do you save PDFs and HTML in graph database?
- Saving PDF and HTML files in a graph database is handled through the ADD command, which supports custom ingestion flows. Files are read, processed into chunks of text, and passed to an LLM with a system prompt developed in-house to generate a graph representation. This transforms unstructured content into structured entities and relationships. When the source data is deterministic, such as from a relational database, the ADD command can bypass the LLM and translate the data directly into graph form in a one-to-one manner, ensuring accuracy and reducing ambiguity. Ontologies can also be defined manually or ingested automatically and are merged with the LLM-generated graph to provide grounding and reduce noise. An example of this process is available through the Cognee and Memgraph integration, supported by a demonstration notebook.
- Is ontology part auto-generated from the data or manually implemented?
- The open-source version currently supports manually defined ontologies that can be loaded into the system. Auto-generation of ontologies is available, but it is not included in the open-source product and is offered as part of the commercial solution.
- How are you dealing with entity disambiguation, i.e. making sure different references to the same entity are stored into the same node?
- Entity disambiguation is addressed through a combination of approaches. One method involves running multiple passes and then deduplicating entities, where consistency across a high number of runs increases confidence in the result. Cross-checking references from the original source documents also helps maintain accuracy by preserving the full path and context of each mention. Built-in deduplication logic further supports this process. In addition, combining deterministic engineering techniques with repeated LLM queries improves reliability, and in some cases, results are validated by asking a different LLM to review the output of the first, reducing bias and increasing accuracy.
- How to trust on LLM graph generation?
- Trust in LLM-based graph generation is approached similarly to trust in human-managed databases. Manual approaches, such as those used in the semantic web era, required constant oversight and eventually became unsustainable. While LLMs are not error-free and improvements are still needed, they offer a reliable way to handle large volumes of unstructured or repetitive data that would otherwise be tedious for humans to manage. At present, this represents the most effective option available for generating graphs from unstructured information.
- What type of embeddings does Cognee use and what is recommended?
- Cognee primarily uses large text embeddings from OpenAI, which work effectively out of the box. Other embedding models have been tested, but no significant improvements have been observed compared to OpenAI’s approach. Since a graph layer is added on top, variability in performance across different embeddings is reduced, making OpenAI embeddings a reliable choice without the need for heavy optimization.
- How do you manage existing graph updates, without having duplicate nodes?
- Graph updates are handled by deleting the affected chunk and all associated nodes before replacing them with the updated version. Incremental updates on unstructured data are difficult to implement reliably because changes to one chunk often affect the alignment of subsequent chunks. While incremental engineering is possible, it becomes expensive and error-prone. For this reason, the current approach is to clean and replace rather than update incrementally. A generalized delete logic has been implemented and is being extended further, with broader support expected soon.
- Once the knowledge graph is created, how can it be verified that all information from the provided documentation has been captured?
- Verification is performed using an evaluation framework based on domain-specific question-and-answer pairs. Expected answers are defined for key questions, such as financial metrics or operational details relevant to the documentation. The knowledge graph is then queried with these questions, and the returned answers are compared against the expected results. This process helps identify gaps or inaccuracies, allowing iterative improvements to ensure the graph accurately reflects the source information.
- Is it mandatory for Cognee to use the knowledge graph it creates for agent memory, or can other knowledge graphs be used?
- Knowledge graphs can be created independently and brought into Cognee using a custom
ADDfunction, where Cognee’s logic can then be applied to enrich them. Using external knowledge graphs is not prohibited, though dedicated integrations for such cases have not yet been developed. Contributions to extend this functionality are definitely welcome.
- Knowledge graphs can be created independently and brought into Cognee using a custom
Further Reading
- Demo: Cognee + Memgraph Demo Notebook
- Blog: Cognee + Memgraph: How To Build An Intelligent Knowledge Graph Using Hacker News Data
- Blog: Options for Building GraphRAG: Frameworks, Graph Databases, and Tools
- Blog: LLM Limitations: Why Can’t You Query Your Enterprise Knowledge with Just an LLM?
- Blog: Why LLMs Need Better Context?
- Research Paper: Optimizing the Interface Between Knowledge Graphs and LLMs for Complex Reasoning