
Inside SynaLinks: How Knowledge Graphs Power Neuro-Symbolic AI
We recently hosted a Memgraph Community Call with Dr. Yoan Sallami, PhD researcher and CEO of SynaLinks. The session, From Tensors to Triplets: Redefining Deep Learning with Knowledge Graph Based Agents, explored how neuro-symbolic AI frameworks can bring structure, context, and flexibility to LLM-powered systems.
If you couldn’t join live, don’t worry. You can catch the full recording here. Below are some of the highlights from the talk to give you a sense of what was covered.
Key Takeaway 1: What is SynaLinks?
Dr. Sallami introduced SynaLinks as a neuro-symbolic AI framework forked from Keras. His motivation was straightforward: most LLM frameworks are rigid and hard to adapt for business use. Inspired by the modularity of Keras, he reimagined it to better support knowledge graph–driven applications.
At its core, SynaLinks focuses on three areas:
- Workflows (Pipelines): Structured directed acyclic graphs (DAGs) of modules.
- Knowledge Graphs: Flexible, schema-driven data models.
- Optimization: Robustness and usability in business contexts.
The goal is to make building dynamic, self-organising agents easier and more practical.
Key Takeaway 2: Building Workflows and Pipelines
Pipelines in SynaLinks are structured as DAGs. Each module processes data and passes the result along to the next step. Inputs and outputs are defined using Pydantic models, ensuring consistency across the entire pipeline.
The programming style feels familiar to anyone who has used Keras. It can be described as a very easy-to-use, declarative style. To keep LLM outputs well-formed, constraint-based decoding is used so results always respect the expected JSON schema.
Key Takeaway 3: Knowledge Graphs as Data Models
Knowledge graphs in SynaLinks are treated like data models. The only strict rule is that every entity and relation must have a label. Beyond that, the schema is flexible enough to adapt to different business needs.
Relations are expressed as subject–label-object and can carry metadata like names or descriptions. Because everything, from entities to modules, is implemented in Pydantic, data serialization and schema generation become consistent.
Key Takeaway 4: Extraction Pipelines
There are multiple strategies for extracting entities and relations. Each comes with its own trade-offs and best-use cases.
One-Stage Extraction
In this approach, a single LLM handles everything in one pass. It identifies entities and relations simultaneously. The advantage is simplicity and speed. The downside is less control and higher chances of errors when the task is complex.
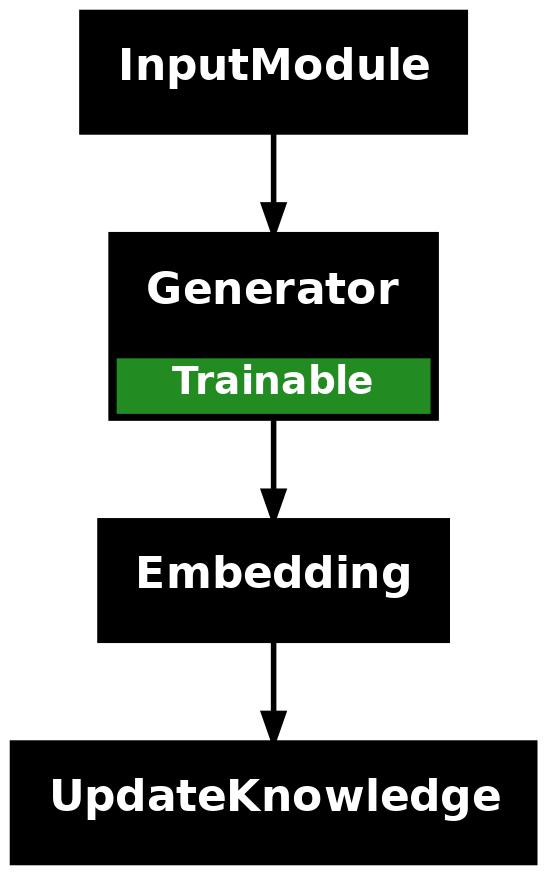
Two-Stage Extraction
Here the process is broken into two steps. First, entities are extracted. Then relations are identified using those entities as context. This makes the pipeline more accurate and easier to debug, though slightly more involved to set up.
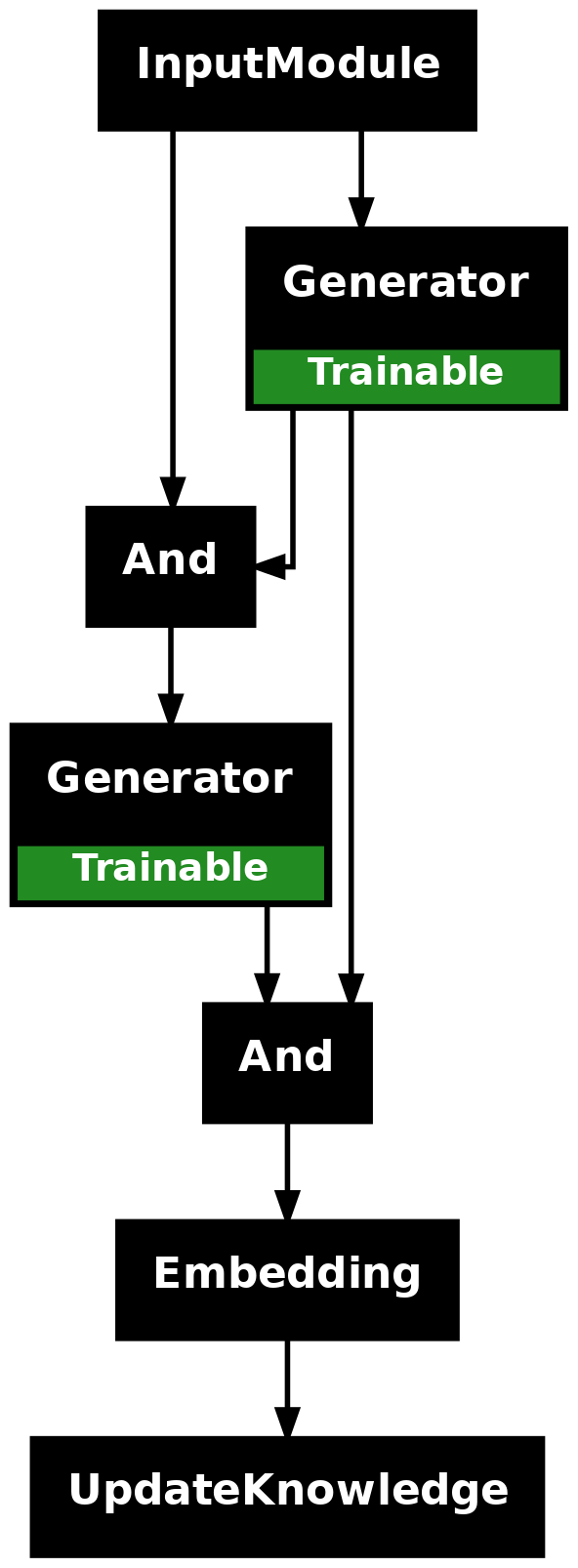
Multi-Stage Extraction
With multi-stage extraction, different generators specialize in subsets of the data—for example, one for cities, one for events, and another for organizations. Their outputs are then merged. This provides maximum control, helps avoid overloading the LLM, and can even allow partial graphs when some generators fail.
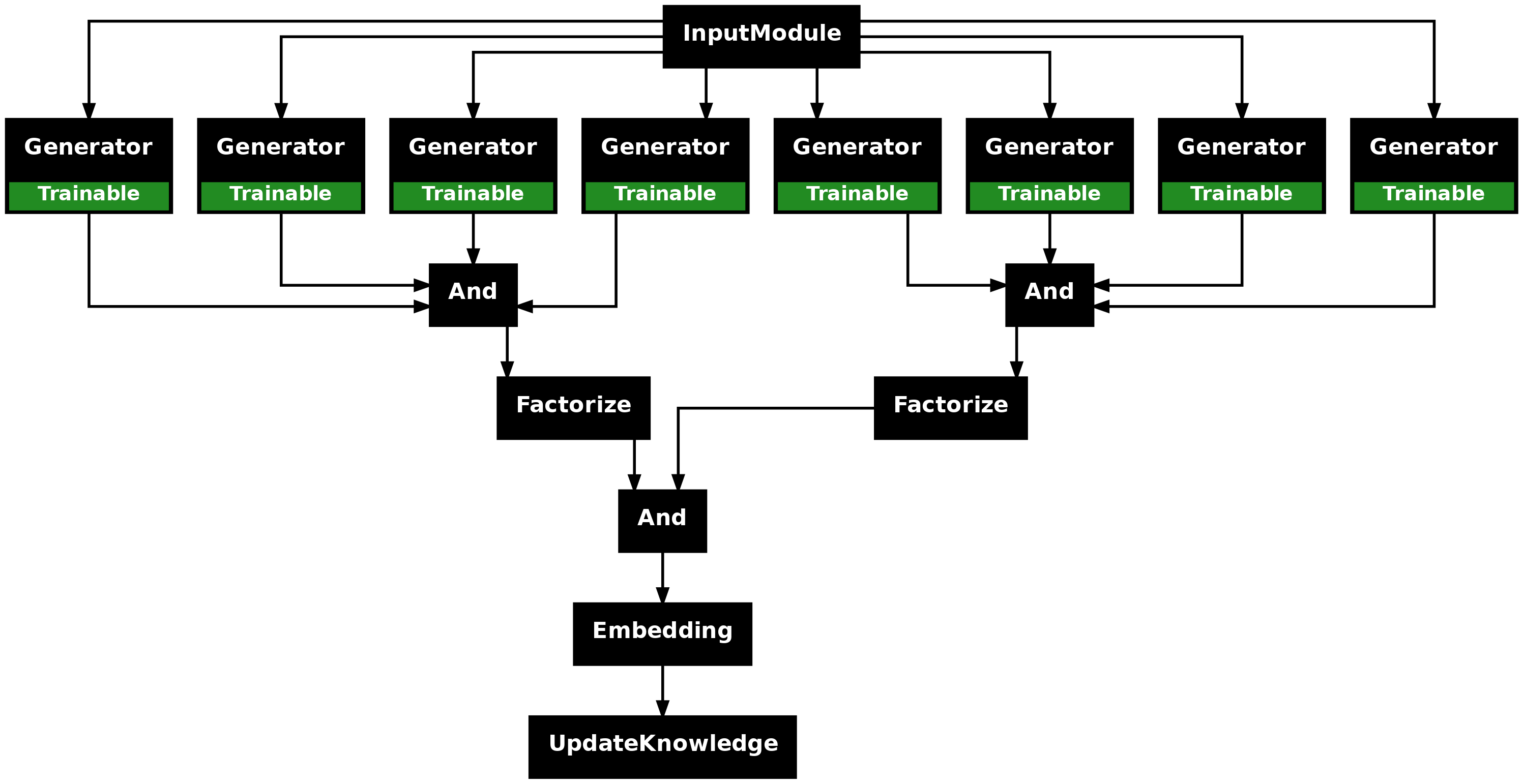
Relation-Only Extraction
Another variant is relation-only extraction. By focusing just on relations, you ensure that all entities are connected, avoiding orphan nodes and keeping the graph clean.
Key Takeaway 5: Memgraph in Action - Demo Overview
The demo showed how SynaLinks integrates directly with Memgraph. Deduplication is handled with Memgraph’s vector index. A similarity search decides whether to update an existing node or create a new one. This is powered by HNSW (Hierarchical Navigable Small World) indexing, which is faster than traditional matching algorithms.
Multi-document ingestion is supported as well. Entities from different pages or files are merged into a single unified knowledge graph.
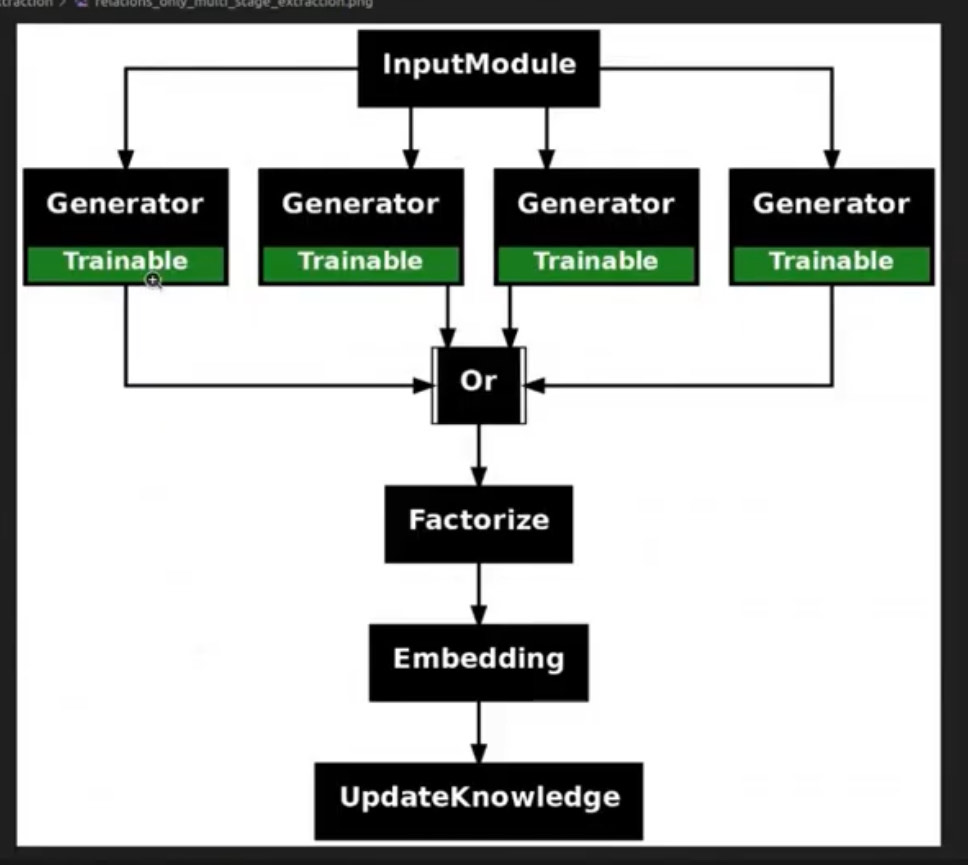
During the live demo in Memgraph Lab, the graph grew in real time as documents were added. Plus, relation-only extraction ensured there were no orphan nodes.
A more detailed look at the demo can be seen in the full community call recording.
Key Takeaway 6: Real-World Use Cases and Guidance
Knowledge graphs are not abstract ideas, they are being applied in real-world mission-critical use cases today.
- A security company might model incidents, people, and hosts.
- A biology company could map molecules, effects, and product compositions.
- Finance and healthcare firms need strict data cleanliness, which makes structured knowledge graphs essential.
Dr. Sallami also shared some practical best practices for best results:
- If you already have structured data, write a script to extract from it first.
- Use LLMs only when handling unstructured content like PDFs, logs, or free text reports.
- Always design schemas with domain experts. A poorly designed schema produces a poor graph, no matter how advanced the technology.
Get the Full Story
This blog post only scratches the surface of the fascinating insights shared by Dr. Sallami. To get the full context, see the demo in action, and learn how to build your own neurosymbolic AI systems, watch the full community call on demand: From Tensors to Triplets: Redefining Deep Learning with Knowledge Graph Based Agents
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
- Have you tested this with entities which are defined across multiple unstructured inputs (different pages of a PDF or files)?
- Yes, that’s actually something we’ve tested. The challenge in that case is handling duplication of entities in the graph so you can connect relationships from different pages and documents into one unified view. In SynaLinks, this happens automatically using the vector index of the graph database. Instead of running a Cypher query that simply creates or merges a node, the query also performs a similarity search. If no similar node exists, we create a new one, and if a similar node does exist, we update it. That way, we avoid duplication. By using the hierarchical small-world k-nearest neighbor search in the vector database, we can do this deduplication at high speed, instead of relying on heavier approaches like the Hungarian algorithm. The heavy computation is handled by the graph database itself; we just orchestrate it in a smart way.
- Does the generator recourse to Cypher or another language to feed the database?
- Yes, exactly. The data model is converted into Cypher in order to update the graph database.
- Do you think this graph construction work can be simplified in the future?
- I’ve experimented with using agents like Cursor to help generate the schema, and that can simplify things a bit. Since the data structure is Pydantic-style, LLMs are generally good enough to assist with this. The challenge, however, is that schema design in knowledge graphs usually needs to be done by someone who understands the problem they’re trying to solve. An LLM can help write the schema, but it can’t really capture the right modeling decisions. The hard part isn’t writing the schema, it’s modeling by figuring out how to solve your problem, what queries you’ll need, the purpose of the knowledge graph, and how you’ll use it. That’s also why we didn’t want to create an overly opinionated way of describing nodes and edges. Instead, we reduced it to the minimum necessary so that the system can connect everything, retrieve the right nodes, and still stay flexible. In our business applications, each client has different needs, so a one-size-fits-all schema wouldn’t be efficient as you might end up invalidating your work when the use case changes.
- How can someone begin working with SynaLinks using an existing knowledge graph? Is it necessary to write code to define each node type and relationship type?
- Yes, you can work with an already existing database, but you’ll need to define the schema you’re using. For the system to work properly, a schema is required. Right now, that means you’ll need to define your schema in Pydantic in order to connect to your existing graph database. In the future, we may add methods to automatically extract the schema from an existing graph and convert it into a Pydantic structure. That way, you wouldn’t need to define it manually; but at the moment, manual schema definition is necessary.
- In your experience, what kind of data is difficult to capture into entities? Or have you been relatively successful with most examples?
- Almost any problem can be modeled as a graph or knowledge graph, but it doesn’t always make sense to do so. It depends on what you want to achieve. Knowledge graphs are especially strong when dealing with relational data. For example, you can use them for a standard RAG setup by storing chunks and documents, similar to Microsoft’s Graph RAG. The main limitation is that graph databases model everything as triplets: subject, relation, object. Unlike ontologies, you don’t get reasoning on top of relations. But property graphs give you more freedom. You can attach metadata to both nodes and relationships, which makes them flexible and powerful. That said, knowledge graphs are always domain- and problem-specific. There’s no one-size-fits-all solution. A security company, for example, would need to build a graph tailored to its specific needs. Some problems are better solved with knowledge graphs, others without. But, in general, connected data often provides the clearest insights.
- You currently relate relationships with the same name, by appending numbers? What if the relationships are not coherent, i.e., ambiguous? This happens in evolving knowledge domains, especially when different disciplines are involved. Is there a table that relates the numbers to the conflicting relation nodes?
- Ambiguity can mean different things depending on whether you’re looking at it from a human perspective or from an LLM’s perspective. For LLMs, it’s important to remember that they reason in tokens. If you have two relations that are almost the same and share many tokens (for example, “contains” and “not contains”), the LLM can confuse them. In the embedding space, similar tokens are mapped close together, which increases the risk of mistakes. One way to reduce this problem is to use relation names that are as distinct as possible, even if they end up having similar meanings. Making them token-wise different gives the LLM clearer boundaries when extracting knowledge. If you’re just starting out and rely on an agent like Cursor to generate a schema, you might get something that looks correct but isn’t coherent. Without the expertise to spot those mistakes, you risk wasting time or even money if that schema becomes the basis of your knowledge graph. Ultimately, if your schema isn’t coherent, your knowledge graph won’t be coherent either.
Further Reading
- Blog: Memgraph AI Toolkit: A Codebase for Graph-Powered Applications
- Community Call: From Chaos to Context: Building Knowledge Graphs with AI Agents and Vector Search
- Blog: How to build multi-agent RAG system with LlamaIndex?
- Docs: Memgraph in GraphRAG Use Cases
- Webinar: Talking to Your Graph Database with LLMs Using GraphChat
- Blog: 4 Real-World Success Stories Where GraphRAG Beats Standard RAG