![How to Benchmark Memgraph [or Neo4j] with Benchgraph?](/_next/image?url=%2Fimages%2Fblog%2Fbenchmark-memgraph-or-neo4J-with-benchgraph%2Fcover.png&w=3840&q=75)
How to Benchmark Memgraph [or Neo4j] with Benchgraph?
Preparing, running, and evaluating benchmarks is a tedious and time-consuming process. The hardest step in the whole process of benchmarking is setting up a “production-like” scenario. There are a lot of databases in production environments, a bunch of them serve different purposes, run different workloads, and are operated in different ways. This means it is impossible to simulate your specific workload and how your database will operate, so doing your own benchmarking is an important factor. On top of that, every use-case has some different metric that is used to evaluate the performance of the system.
Since we are running benchgraph in our CI/CD environment, we decided to do small tweaks to benchgraph to ease the process of running benchmarks on Memgraph (and Neo4j 🙂) on your hardware, on your workload, and under conditions that matter to you. At the moment, the focus was on executing pure Cypher queries.
To be able to run these benchmarks you need to have at least Python 3.7 and Docker installed and running, and a very basic knowledge of Python.
Before you start working on your workload, you need to download benchgraph zip or pull Memgraph GitHub repository. If you are using the Memgraph repository just position yourself into /tests/mgbench, if you are using zip just unzip it and open the folder in your favorite IDE or code editor.
Add your workload
In the project structure you will see various different scripts, take a look at the Benchgraph architecture for a more detailed overview of what each of these scripts does. But the important folder here is the workloads folder, where you will add your workload. You can start by creating a simple empty Python script, and giving it a name, in our case it is demo.py.
In order to specify the workload that you will be able to run on Memgraph and Neo4j, you need to implement some details into your script. Here are 5 steps you need to do:
- Inherit the workload class
- Define a workload name
- Implement the dataset generator method
- Implement the index generator method
- Define the queries you want to benchmark
These five steps will result in something similar to this simplified version of demo.py example:
import random
from workloads.base import Workload
class Demo(Workload):
NAME = "demo"
def dataset_generator(self):
queries = []
for i in range(0, 10000):
queries.append(("CREATE (:NodeA {id: $id});", {"id": i}))
queries.append(("CREATE (:NodeB {id: $id});", {"id": i}))
for i in range(0, 50000):
a = random.randint(0, 9999)
b = random.randint(0, 9999)
queries.append(
(("MATCH(a:NodeA {id: $A_id}),(b:NodeB{id: $B_id}) CREATE (a)-[:EDGE]->(b)"), {"A_id": a, "B_id": b})
)
return queries
def indexes_generator(self):
indexes = [
("CREATE INDEX ON :NodeA(id);", {}),
("CREATE INDEX ON :NodeB(id);", {}),
]
return indexes
def benchmark__test__get_nodes(self):
return ("MATCH (n) RETURN n;", {})
def benchmark__test__get_node_by_id(self):
return ("MATCH (n:NodeA{id: $id}) RETURN n;", {"id": random.randint(0, 9999)})
Let’s break this demo.py script into smaller pieces and explain the steps you need to do so it is easier to understand what is happening.
1. Inherit the workload class
The Demo class has a parent class Workload. Each custom workload should be inherited from the base Workload class. This means you need to add an import statement on top of your script and specify inheritance in Python.
from workloads.base import Workload
class Demo(Workload):2. Define the workload name
The class should specify the NAME property. This is used to describe what workload class you want to execute. When calling benchmark.py, the script that runs the benchmark process, this property will be used to differentiate different workloads.
NAME = "demo"3. Implement the dataset generator method
The class should implement the dataset_generator() method. The method generates a dataset that returns the list of tuples. Each tuple contains a string of the Cypher query and dictionary that contains optional arguments, so the structure is as follows [(str, dict), (str, dict)...]. Let's take a look at how the example list would look like:
queries = [
("CREATE (:NodeA {id: 23});", {}),
("CREATE (:NodeB {id: $id, foo: $property});", {"id" : 123, "property": "foo" }),
...
]As you can see, you can pass just a Cypher query as a pure string without any values in the dictionary.
("CREATE (:NodeA {id: 23});", {}),Or you can specify parameters inside a dictionary. The variables next to $ sign in the query string will be replaced by the appropriate values behind the key from the dictionary. In this case, $id is replaced by 123, and $property is replaced by foo. The dictionary key names and variable names need to match.
("CREATE (:NodeB {id: $id, foo: $property});", {"id" : 123, "property": "foo" })Back to our demo.py example, in the dataset_generator() method, here you specify queries for generating a dataset. That means all queries for dataset generation are based on this specified list of queries. Keep in mind that you can't import dataset files (such as CSV, JSON, etc.) directly since the database is running in Docker, you need to convert dataset files to pure Cypher queries. But that should not be too hard to do in Python.
In the demo.py, the first for loop is preparing the queries for creating 10000 nodes with the label NodeA and 10000 nodes with the label NodeB. We are using random class to generate a random sequence of integer IDs. Each node has an id between 0 and 9999. In the second for loop, queries for connecting nodes randomly are generated. There is a total of 50000 edges, each connected to random NodeA and NodeB.
def dataset_generator(self):
for i in range(0, 10000):
queries.append(("CREATE (:NodeA {id: $id});", {"id" : i}))
queries.append(("CREATE (:NodeB {id: $id});", {"id" : i}))
for i in range(0, 50000):
a = random.randint(0, 9999)
b = random.randint(0, 9999)
queries.append((("MATCH(a:NodeA {id: $A_id}),(b:NodeB{id: $B_id}) CREATE (a)-[:EDGE]->(b)"), {"A_id": a, "B_id" : b}))
return queries4. Implement the index generator method
The class should also implement the indexes_generator() method. This is implemented the same way as the dataset_generator() method, instead of queries for the dataset, indexes_generator() should return the list of indexes that will be used. Of course, you can include constraints and other queries you have in your workload. The list of queries from indexes_generator() will be executed before the queries for the dataset generator. The returning structure again is the list of tuples that contains query string and dictionary of parameters. Here is an example:
def indexes_generator(self):
indexes = [
("CREATE INDEX ON :NodeA(id);", {}),
("CREATE INDEX ON :NodeB(id);", {}),
]
return indexes5. Define the queries you want to benchmark
Now that your database has indexes and the dataset imported, you can specify what queries you wish to benchmark on the given dataset. Here are two queries that demo.py workload defines. They are written as Python methods that return a single tuple with a query and dictionary, like in the data generator method.
def benchmark__test__get_nodes(self):
return ("MATCH (n) RETURN n;", {})
def benchmark__test__get_node_by_id(self):
return ("MATCH (n:NodeA{id: $id}) RETURN n;", {"id": random.randint(0, 9999)})
The necessary details here are that each of the methods you wish to use in the benchmark test needs to start with benchmark__ in the name, otherwise, it will be ignored. The complete method name has the following structure benchmark__group__name. The group can be used to execute specific tests, but more on that later.
From the workload setup, this is all you need to do. The next step is running your workload.
Run benchmarks on your workload
Let's start with the most straightforward way to run the demo.py workload from the example above. The main script that manages benchmark execution is benchmark.py, it accepts a variety of different arguments, but we will get there. Open the terminal of your choice, and position yourself in the downloaded benchgraph folder.
To start the benchmark, you need to run the following command:
python3 benchmark.py vendor-docker --vendor-name ( memgraph-docker || neo4j-docker ) benchmarks demo/*/*/* --export-results result.json --no-authorization
For example, to run this on Memgraph, the command looks like this:
python3 benchmark.py vendor-docker --vendor-name memgraph-docker benchmarks “demo/*/*/*” --export-results results.json --no-authorization
After a few seconds or minutes, depending on your workload, the benchmark should be done with execution. In your terminal, you should see something similar to this:
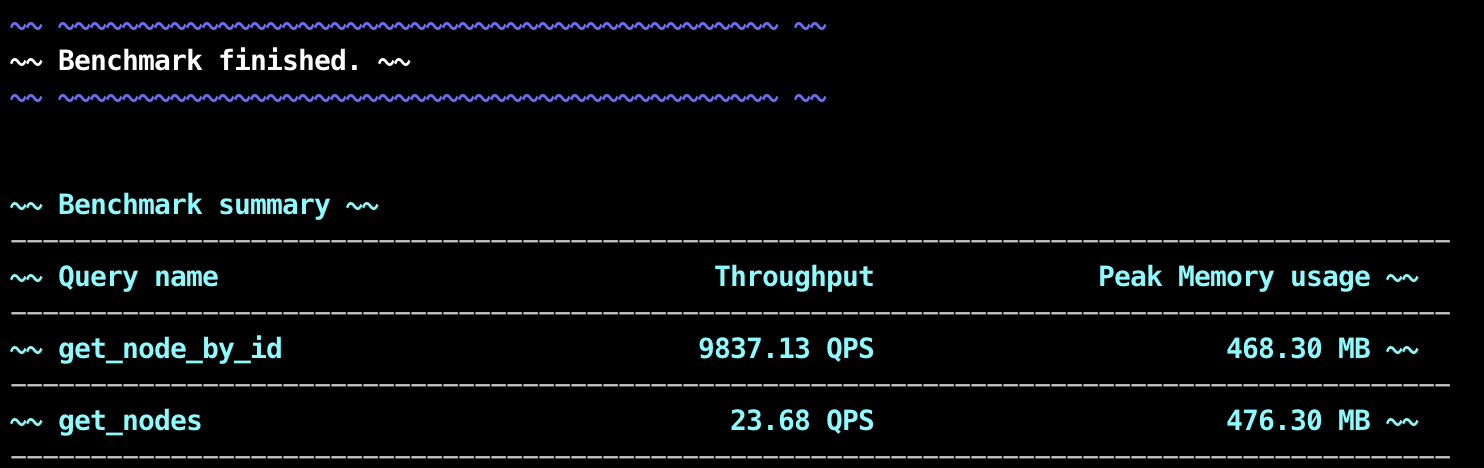
On the image in the end, you can see the summary of results, feel free to explore and write different queries for Memgraph to see what type of performance you can expect.
To run this same workload on Neo4j, just change –vendor-name argument to neo4j-docker. If you stumble upon the issues with setting specific indexes or queries, take a look at how to run the same workload on different vendors.
How to compare results
Once the benchmark has been run on both vendors, or with different configurations, the results are saved in a file specified by --export-results argument. You can use the results files and compare them against other vendor results via the compare_results.py script:
python3 compare_results.py --compare path_to/run_1.json path_to/run_2.json --output run_1_vs_run_2.html --different-vendors
The output is an HTML file with a visual representation of the performance differences between two compared vendors. The first passed summary JSON file is the reference point. Feel free to open an HTML file in any browser at hand.
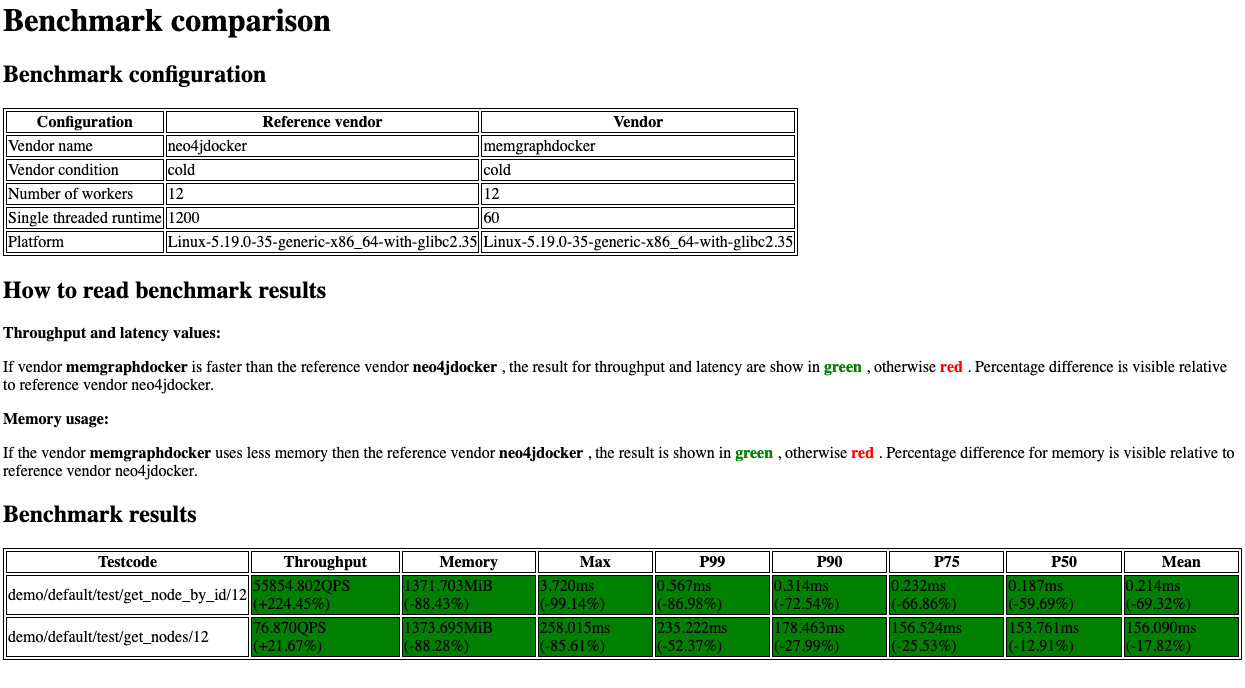
How to configure the benchmark run
Configuring your benchmark run will enable you to see how things change under different conditions. Some arguments used in the run above are self-explanatory. For a full list take a look at the benchmark.py script. For now, let's break down the most important ones:
-
NAME/VARIANT/GROUP/QUERY- The argumentdemo/*/*/*says to execute the workload nameddemo, and all of its variants, groups, and queries. This flag is used for direct control of what workload you wish to execute. TheNAMEhere is the name of the workload defined in the Workload class.VARIANTis an additional workload configuration, which will be explained a bit later.GROUPis defined in the query method name, andQUERYis the query name you wish to execute. If you want to execute a specific query fromdemo.py, it would look like this:demo/*/test/get_nodes. This will run ademoworkload on allvariants, in thetestquery group and queryget_nodes. -
--single-threaded-runtime-sec- The question at hand is how many of each specific queries you wish to execute as a sample for a database benchmark. Each query can take a different time to execute, so fixating a number could yield some queries finishing in 1 second and others running for a minute. This flag defines the duration in seconds that will be used to approximate how many queries you wish to execute. The default value is 10 seconds, this means thebenchmark.pywill generate a predetermined number of queries to approximate single treaded runtime of 10 seconds. Increasing this will yield a longer running test. Each specific query will get a different count that specifies how many queries will be generated. This can be inspected after the test. For example, for 10 seconds of single-threaded runtime, the queries from demo workloadget_node_by_idgot 64230 different queries, whileget_nodesgot 5061 because of different time complexity of queries. -
--num-workers-for-benchmark- The flag defines how many concurrent clients will open and query the database. With this flag, you can simulate different database users connecting to the database and executing queries. Each of the clients is independent and executes queries as fast as possible. They share a total pool of queries that were generated by the--single-threaded-runtime-sec. This means the total number of queries that need to be executed is shared between a specified number of workers. -
--warm-up- The warm-up flag can take three different arguments,cold,hot, andvulcanic. Cold is the default. There is no warm-up being executed,hotwill execute some predefined queries before the benchmark, whilevulcanicwill run the whole workload first before taking measurements. Here is the implementation of warm-up
How to run the same workload on the different vendors
The base workload class has benchmarking context information that contains all benchmark arguments used in the benchmark run. Some are mentioned above. The key argument here is the --vendor-name, which defines what database is being used in this benchmark.
During the creation of your workload, you can access the parent class property by using self.benchmark_context.vendor_name. For example, if you want to specify special index creation for each vendor, the indexes_generator() could look like this:
def indexes_generator(self):
indexes = []
if "neo4j" in self.benchmark_context.vendor_name:
indexes.extend(
[
("CREATE INDEX FOR (n:NodeA) ON (n.id);", {}),
("CREATE INDEX FOR (n:NodeB) ON (n.id);", {}),
]
)
else:
indexes.extend(
[
("CREATE INDEX ON :NodeA(id);", {}),
("CREATE INDEX ON :NodeB(id);", {}),
]
)
return indexesThe same applies to the dataset_generator(). During the generation of the dataset, you can use special types of queries for different vendors, to simulate identical scenarios.
Happy benchmarking
Have fun benchmarking Memgraph and Neo4j! We would love to hear more about your results on our Discord server. If you have issues understanding what is happening, take a look at Benchgraph architecture or just reach out!