Cutting the Noise: Making GraphRAG Work with Massive Enterprise Schemas
Large enterprises often struggle with one fundamental challenge. How can large language models (LLMs) stay accurate when their graphs are massive, complex, and full of noise?
GraphRAG solves this problem through a simple yet powerful trick. Instead of feeding the model more data, it teaches the model to reason through structure. Rather than fine-tuning on your dataset, GraphRAG uses your Graph Schema to help the LLM understand how different entities are connected. The result is an explainable, composable, and scalable reasoning process grounded in the truth of your data.
In this blog, we explore how GraphRAG achieves that and how fine-grained access controls in Memgraph help LLMs focus on what truly matters inside large enterprise schemas.
The Challenge of Large Schemas
Enterprise graphs are rarely small. They often include thousands of node labels and hundreds of relationship types, representing data from many different systems.
Adding the entire schema to an LLM’s context may ground it in truth, but it also floods the model with details that are not relevant to the question. The LLM ends up wasting attention trying to understand every label and relationship instead of focusing on the real task.
To make the model truly useful, it needs a way to see only what matters. That means filtering the schema so that the LLM reasons within a clear, scoped context instead of drowning in unnecessary information.
So, how do we help the LLM focus only on what’s relevant?
Meet Jim: The LLM as a New Employee
Let’s take a step back. Imagine your LLM as a new senior developer named Jim.
It is Jim’s first day at a supply chain management company. He is technically sharp, knows his tools well, and is fluent in Cypher queries because he is already familiar with Memgraph documentation.
He might make a few syntax errors here and there, but thanks to Memgraph’s clear error messages, he can quickly learn, adjust, and refine his queries.
Jim’s first task at his new job is to analyze whether all suppliers contribute to the final products.
However, the company’s Memgraph database contains more than just supply chain data. It also includes financial analysis, fraud detection, and customer 360 insights.
The schema? Roughly 1,000 node labels and 100 edge types. That’s a lot to take in!
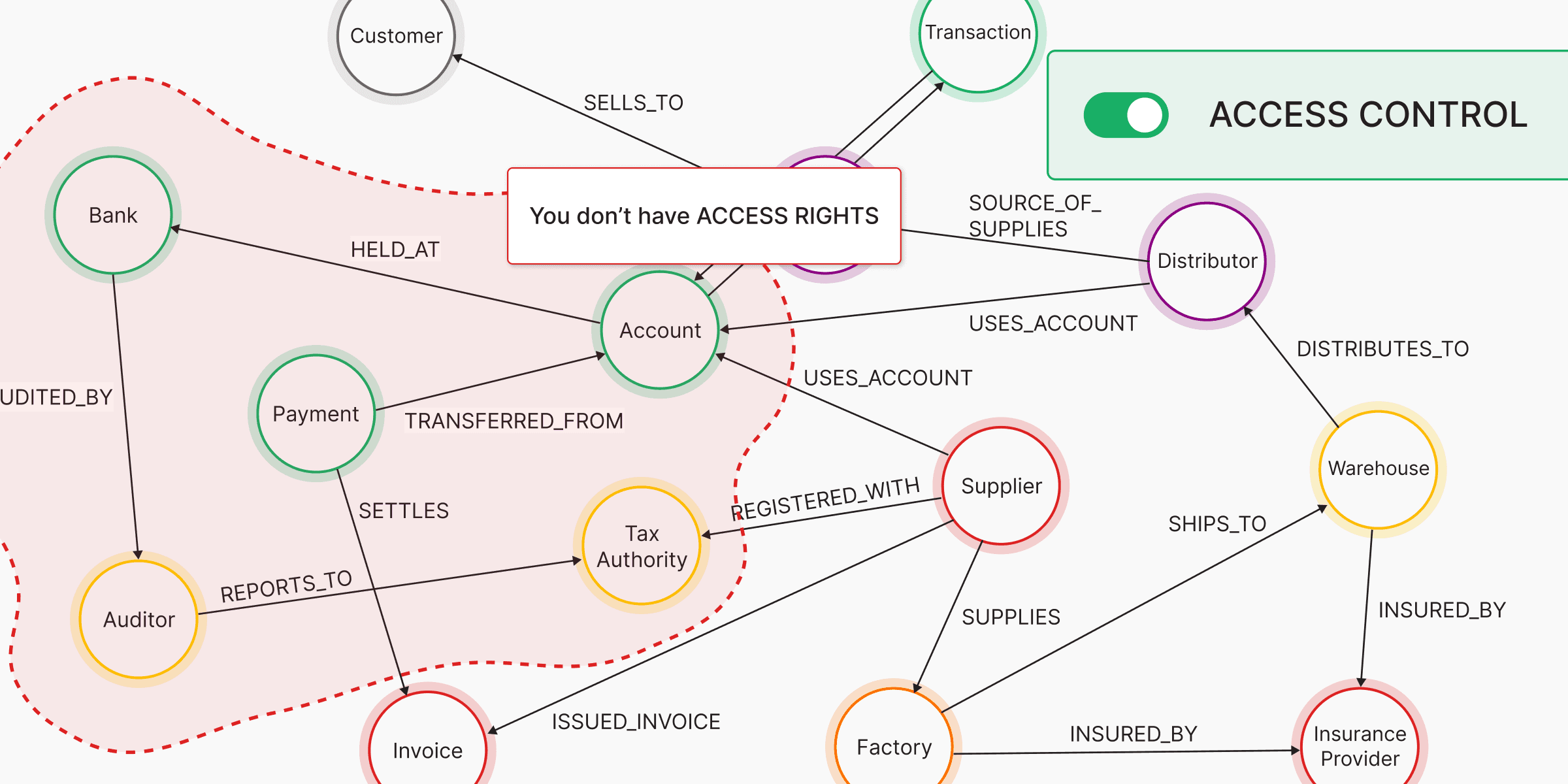
So, Jim does the smart thing: he asks the database admin which parts of the schema are relevant. The admin points him to just 5 node labels and 1 edge type.
With that, Jim can focus, query effectively, and deliver results quickly.
Fine-Grained Access Control: The Hidden Hero
So how does this work in Memgraph?
The answer lies in fine-grained access control, also known as label-based access control. It lets administrators grant users access to only the parts of the schema relevant to their use case.
For example:
GRANT READ ON LABELS :Supplier, :Ingredient, :FinalProduct TO jim;
GRANT READ ON EDGE_TYPES :FORMS, :SHIPS TO jim;
With these privileges, Jim can run:
SHOW SCHEMA INFO;
And instead of a massive, unreadable schema, he sees a clean, focused subset:
(:Supplier)-[:SHIPS]->(:Ingredient)-[:FORMS]->(:FinalProduct)
Here’s a visual representation of this change:
Jim now works efficiently within his domain, free from irrelevant noise. If helater moves to another project, his privileges and schema visibility can be easily adjusted accordingly.
Teaching the LLM to Focus Like Jim
This principle applies directly to LLMs.
When an LLM’s prompt is filled with a massive schema, confusion often follows.
Instead, we can use Memgraph’s Fine-Grained Access Control to limit the schema context and help the LLM “see” only what it needs to reason effectively.
That’s why in Memgraph, SHOW SCHEMA INFO works seamlessly with fine-grained access control. You can create users with scoped privileges so that each LLM session (or agent) accesses only the schema subset relevant to its task.
This approach doesn’t just reduce noise, it creates focus, clarity, and expertise. Each model instance becomes an expert in its domain, much like Jim mastering his first assignment.
While chunking a large schema into pieces can help, it still risks introducing irrelevant information. With fine-grained access control, you can design LLM interactions that are scoped, explainable, and domain-specific. It is the cleanest and most reliable way to handle large enterprise graph contexts.
Wrapping Up
When it comes to GraphRAG in large organizations, more context is not always better. The goal is to provide the right context.
By grounding LLMs through Fine-Grained Access Controls, you allow them to reason accurately without being distracted by noise.
This approach helps enterprises build LLMs that are not just smarter but also sharper, focused on truth, guided by structure, and efficient at scale.
So the next time you think about optimizing your GraphRAG pipeline, remember Jim, the LLM that learned to focus.