
MCP + Memgraph: Building a Reliable RAG Pipeline
Building natural‑language Q&A over graph data is becoming a common goal for teams working with LLMs, and this community call explored one such real implementation.
Orbis Holding shared their journey of running queries over a Memgraph dataset with nearly 100 million nodes, where users could ask questions in plain English and receive Cypher‑driven answers directly from the graph.
As the system evolved, the team observed several critical challenges with traditional LLM to Cypher workflow.
During this Community Call, Rida El Chall and Affan Abbas walked through where their first LLM to Cypher pipeline struggled, and how moving to an MCP‑based reasoning loop shifted the system from fragile one‑shot execution to something adaptive and inspectable.
If you missed it live, the replay is worth watching for the full breakdown and examples.
Key Takeaway 1: LLM to Cypher Pipeline Architecture
Orbis Holding built a natural language Q&A layer over a Memgraph database with around 100 million nodes. The aim was straightforward: let a user ask questions and receive answers in plain language.
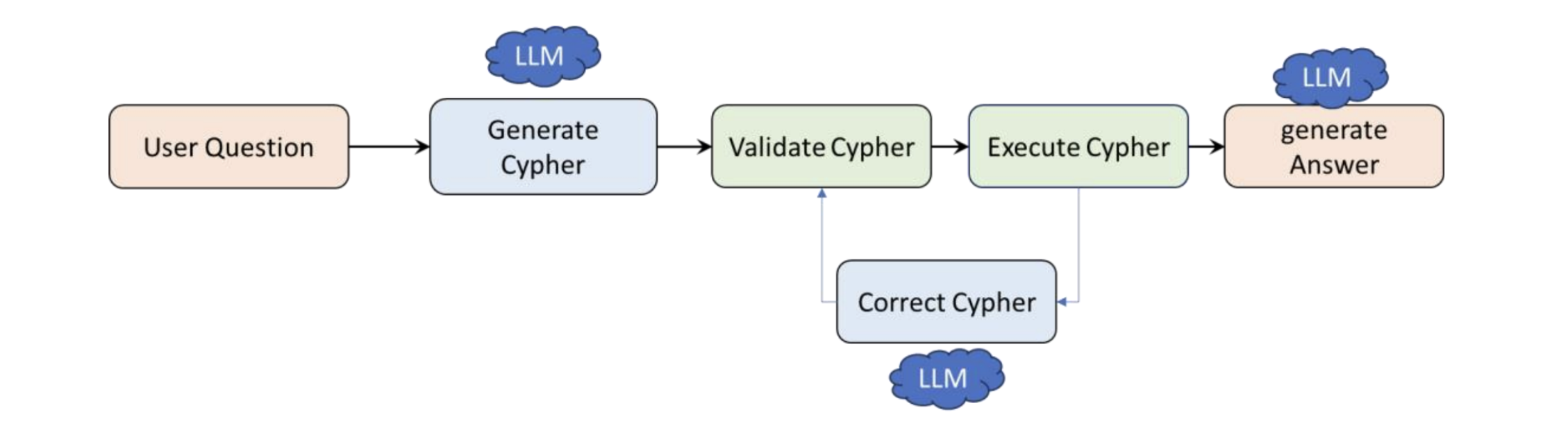
It has three main steps:
- Convert user questions to a graph database (Cypher) query using an LLM model.
- Execute Cypher query on the graph database.
- Generate natural language answer using an LLM model to construct a human-readable response.
This first LLM to Cypher pipeline looked clean, but success only occurred when query structure, values and schema matched perfectly. One mismatch led to either no result or a broken query with no recovery path.
Key Takeaway 2: Why the Old Approach Broke
LLMs can often misinterpret how information is represented inside a graph. Even a simple query can fail quietly if values inside the database follow a format the model does not anticipate. A few real scenarios illustrate this well:
- A request for male users returns nothing when gender is stored as numbers such as
1for males and2for females. - Location attributes may appear in English, Arabic, or both, depending on the record
- Certain properties use unique short-form labels like
GDfor gender. - Multi-hop questions like "Employees at Dubai-based companies who own a car" require moving across several node types. LLM model fails to traverse multi-hop relationships across
person,company,vehicleconnected with edgesLocated_In,Has.
These types of queries often produced silent failures with valid Cypher but empty results, with no error identified.
Key Takeaway 3: Why MCP Was Adopted
The shift toward MCP came from a need for flexibility and deeper insights rather than single‑shot execution.
Model Context Protocol (MCP) by Anthropic provides a standard protocol that connects clients, servers, and LLMs. It is like an USB-C port for AI apps.
Instead of relying on hard‑coded prompts, the team at Orbis required a way to discover tools dynamically, refine queries over multiple steps and inspect how data was actually stored.
MCP introduced that capability through:
- A more dynamic framework that discovers tools instead of depending on predefined prompt logic
- Iterative reasoning loops rather than one‑attempt Cypher generation
- Value inspection tools that reveal actual stored values during query construction
- Schema and relationship exploration tools that guide multi‑hop traversal paths
- Controlled cycle‑based reasoning, enabling retries until a valid query is reached within a set limit
Key Takeaway 4: MCP-Based Architecture
Once MCP enters the picture, query generation becomes an iterative loop rather than a single attempt. Instead of sending one Cypher query and hoping it fits the schema, the system now evaluates, adjusts, and retries through a structured reasoning flow.

Here is how the lifecycle unfolds:
- A user query enters the MCP Client.
- The Client fetches and displays the available MCP Server tools.
- The LLM selects a tool based on the information it has so far.
- The chosen tool is executed and the result is returned.
- The model evaluates whether more information or another tool is needed.
- If the answer is incomplete, the process repeats by often refining Cypher, re‑inspecting values, or exploring new traversal paths.
- The loop continues until a useful answer is reached or the execution cap is met.
Simple questions often resolve in one or two iterations. More complex questions, especially multi‑hop or encoded‑value cases, may take up to eight reasoning cycles to converge on a valid Cypher outcome.
Key Takeaway 5: Old Approach vs MCP-Based Approach
Here’s how the new MCP-based stands out compared to the old LLM to Cypher approach:
| Evaluation Criteria | Old Approach | MCP‐Based Approach |
|---|---|---|
| Integration | Hard-coded and manual | Dynamic and modular through tool registration |
| Reasoning | Limited, fixed workflow | Self-contained reasoning and dynamic tool selection |
| Extensibility | Complex and costly to scale | Scalable multi-server architecture |
| Context Handling | Basic prompts only | Context-rich query with schema, tools, and memory |
Moreover, a benchmark of one hundred questions was tested through both approaches. The old pipeline succeeded on roughly twenty. The MCP version resolved around ninety correctly.
This showcases how much more relaible the new approach is. The system is still being refined and improved for better outcomes. Future improvements are focused on:
- Reducing time to completion since complex queries can sometimes take up to 60–120 seconds.
- Improving tool‐selection efficiency to reduce number of loop cycles required.
Wrapping Up
Enterprise data is rarely simple. Encoding, multilingual attributes and multi-hop questions turn one-shot pipelines into dead ends fast. Memgraph + MCP helped Orbis replace guesswork with iteration.
If you want the full walkthrough, the reasoning loops, and the breakdown of implementation challenges, you can catch the full session recording here.
Q&A
Here’s a compiled list of the questions and answers from the community call Q&A session.
Note that these are paraphrased slightly for brevity. For complete details, watch the full community call recording.
- How were cost overruns controlled?
- Rida: Maximum iteration limit applied (~8 cycles typical). Simple queries resolved in one iteration. Complex queries required 8–9 cycles. End‑to‑end time currently ~1–2 minutes in heavy cases.
- How do you know when you get the desired result from the loop?
- Rida: Verification of the loop result relies on a predefined testing dataset. A collection of ~100 questions exists, each question paired with a validated Cypher query and an expected output. The same question set is executed through the previous pipeline and through the MCP-based pipeline. Output from each run is compared directly against the known Cypher queries and the known expected answers that were prepared in advance by Memgraph and Orbis. A result is considered correct only when generated Cypher and returned data match the predefined ground truth.
- Have you considered multi-shot learning by tracking Cypher across multiple requests in order to improve results?
- Multi–shot learning is already in place through persistent Cypher tracking across requests. Generated Cypher queries, attempted answer paths and selected tools are stored as context and reused in subsequent attempts. Any Cypher query that previously produced no result is flagged and excluded from regeneration, allowing the next iteration to explore alternative paths instead of repeating failed attempts. This process improves query quality over time by guiding the model toward variations that are more likely to return meaningful output.
- What are the biggest technical challenges transitioning from traditional RAG/Graph system towards such MCP-based system?
- Rida: The shift from traditional RAG or Graph architectures to an MCP based system requires a complete redefinition of workflow design. Traditional systems rely on a fixed pipeline, whereas an MCP architecture introduces distributed clients and servers with tool driven execution. The transition demands full redesign of system flow rather than a surface level migration. The primary challenge lies in constructing the MCP client logic. Tool selection, iterative execution, failure handling and stopping conditions must all be defined from scratch. The client must evaluate which tools to call, for how long, when to stop, and how to determine whether a response is sufficient. This loop logic becomes the core engineering difficulty. A second challenge involves elicitation. Clarification prompts must be triggered intelligently to collect missing information, refine requests and avoid dead ends. Designing when to ask questions, when to branch and when to retry becomes critical to stability and output quality. In short, the difficulty is not model output or Cypher generation. The difficulty is architecture, orchestration and decision making inside the MCP client.
- How does evaluation look like for you in production? How do you determine a good vs bad LLM reasoning chain?
- Rida: Evaluation is not yet running in production. Current assessment happens in a controlled testing environment using real user style queries. A benchmark dataset of one hundred questions exists, spanning simple to highly complex queries. Traditional RAG style flow resolved roughly twenty questions correctly. The MCP based approach resolves around ninety questions correctly, establishing a significantly higher accuracy ceiling. Quality is measured by comparing generated Cypher and returned output against predefined ground truth. Expansion of the test suite is ongoing. Additional question sets will determine whether accuracy holds during scale out or degrades over time. Evaluation work is currently focused on stability, latency reduction and dataset growth to refine accuracy further before production rollout.