
Influencers Among Computer Scientists
Introduction
The word "influencer" is on the rise ever since social networks and media started promoting people that had a fanbase so big that they started influencing other people's lives in many different ways. Influencers quickly became instant stars and walking advertisements. This way of living instantly placed roots in different parts of today's society.
Scientists are no exception here. When an article hits the "state of the art" quality, their authors experience fame within their niche, similar to social media influencers and their audience. But who are modern-day influencers in computer science? Let's find out in the following sections!
Computer science bibliography
There is no better source to determine who the most influential computer scientists are than looking into DBLP - computer science bibliography. It is a website that collects and hosts the largest amount of articles published by various computer scientists in different fields of expertise. There you can find an awesome dataset[1] that contains information about paper citations. This dataset will be used to process the information about who is citing whom from 2018 till now.
Influence ranking in a citation network
Interactions between authors can be expressed in the form of a graph. Let's define one specific interaction -> the author cites another author once a citation can be found in the first-mentioned author's publication. This way, we created a network containing around half of the million authors and almost 12 million interactions between them. You can see a fraction of the aforementioned network below.

To evaluate who is the most influential author in this network, we should consider two important factors:
- How many citations the author receives
- The citations from influential authors are more relevant
This set of rules is exactly what the PageRank algorithm does. Google's already established influence measurement algorithm was created by Larry Page and Sergey Brin at Stanford University in 1996. Later on, the algorithm became the powerhouse of Google's search engine, where it was used to measure the importance of web pages. The rest is, of course, history.
Simply put, PageRank outputs the probability that we will, given a random position in the graph, by following a random walk (picking a random path), get to the specific destinations. Intuitively, this probability is higher for nodes that have a larger influence on the graph (more paths lead to it).
In this example, we will use PageRank to measure the importance of authors in the computer science publication library. To achieve this, we'll store the dataset in Memgraph and run the analysis with an algorithm developed using Memgraph's open-source project called MAGE.
Running the example
In this section, we will show you how to run the PageRank procedure in Memgraph MAGE and get the results. Also, we will analyze the running time and check out how popular graph data scientists are doing as "influencers".
First, by running the following command, we will gather the results of the most popular computer scientists from 2018 till now.
CALL pagerank.get() YIELD node, rank
SET node.rank = rank
RETURN node as author, rank
ORDER BY rank DESC
LIMIT 20Since the dataset is huge, we ordered authors by ranking and limited the results. Ranked highest, we can see familiar names of top-notch scientists who influence authors from all over the world.
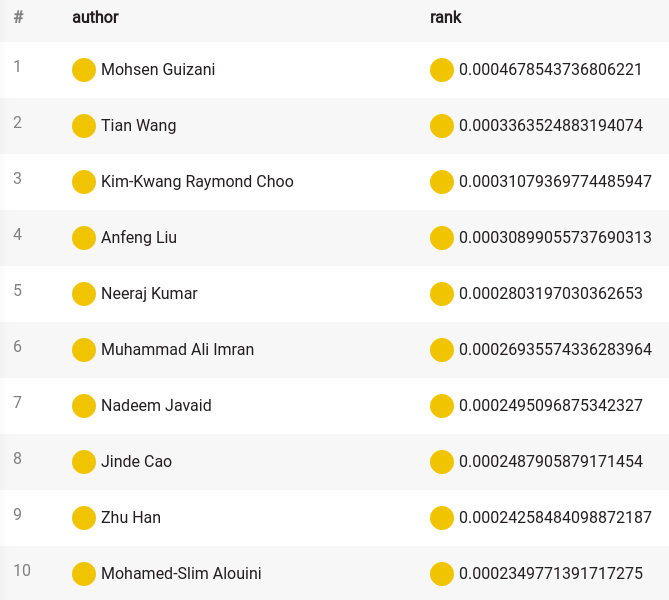
One of the best is certainly Prof. Jure Leskovec, a Slovenian researcher who works in the field of network analysis. His contributions to the field of graph theory are enormous. Let's see how he is doing on this list.
MATCH (jure:Author {name: "Jure Leskovec"})
WITH jure
MATCH (author)
WHERE author.rank > jure.rank
RETURN jure.name, jure.rank, COUNT(author) AS ranking
The results are as expected. Prof. Leskovec is ranked highly on this list. This probably means that he would be proud to see how long it takes to run such a query on Memgraph. Since PageRank is parallelized for the performance gain in MAGE, the following query will give you a little more insight into how fast and scalable PageRank really is.
PROFILE CALL pagerank.get() YIELD node, rank
RETURN node as author, rank
LIMIT 1
12 million edges and 400k nodes in 48 seconds. Brilliant if you have static data!
But, it is not always like that. Now imagine having a constant data flow towards the platform, it would be a disaster to wait 48 seconds for the result of the next influence rank. That's why online algorithms with a few approximations are used. So, hang in there for new blog posts, and you might get the answer on how to tackle the problem of constant reevaluation!
Conclusion
PageRank is an algorithm suitable for measuring the importance and influence of entities in graph data. We demonstrated how simple it can be to gather knowledge from a graph, this time by extracting influence information. Also, we gained some insights into the community of modern-day science leaders in the area of computer science.
If you found this tutorial interesting, you should try out the many other graph analytics algorithms that are part of the MAGE library.
Finally, if you are working on your query module and would like to share it with other developers, take a look at the contributing guidelines. We would be more than happy to provide feedback and add the module to the MAGE repository.
References [1]: Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. ArnetMiner: Extraction and Mining of Academic Social Networks. In Proceedings of the Fourteenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (SIGKDD'2008)