
Context Engineering for Beginners: A Developer’s Guide
LLM apps fail in predictable ways.
They fail when the question is specific to your business. They fail when a user asks for a policy exception. They fail when an agent has to choose the right tool under pressure. They fail when data lives in multiple systems that were never designed to agree with each other.
Many teams try to fix this with better prompts. That helps for tone and structure, but it does not solve the core issue.
In most real enterprise work, the problem is not that the model cannot talk. The problem is that the model cannot reliably find, understand, and scope the information it needs for the task.
That is what context engineering is about.
This guide is written for AI engineers building RAG, GraphRAG, and agentic workflows. It aims to be practical and honest. You will find mental models, architecture patterns, and a checklist you can use on Monday morning.
Why Prompts Are Not Enough
Prompt engineering remains useful. You will still need clear instructions, guardrails in language, and consistent output formats. A well-made prompt can reduce ambiguity and improve the model’s ability to follow intent.
But prompts can’t create enterprise knowledge that is missing from the model’s view of the world. You can’t add all the documents into a prompt.
If your LLM has never seen your internal policies, your product quirks, the way your catalog is actually organised, or your approval rules, then the most polished prompt on earth will not make it produce correct, governed answers.
This is why the same pattern keeps showing up across teams that try to ship LLM features into production.
- Great demo quality
- Fragile production behavior
- Rising costs as they stuff more tokens into the window
- Confusing errors when the model has to combine facts across systems
When this happens, you are dealing with a context problem, not a prompt problem.
What is Context Engineering
Simply put, Context Engineering is the practice of regulating and optimising the AI environment so that the model always sees the right data, with the right structure, under the right rules, at the right moment.
It is not a single trick or library. It is a design discipline that sits alongside prompting, RAG, memory, and tool use, and decides what information is allowed into the model’s field of view.
You can think of the relationship like this:
- Prompt engineering shapes how the model should behave.
- Context engineering shapes what the model is allowed to know and reveal for this task.
Context engineering can be breaken down into four core components:
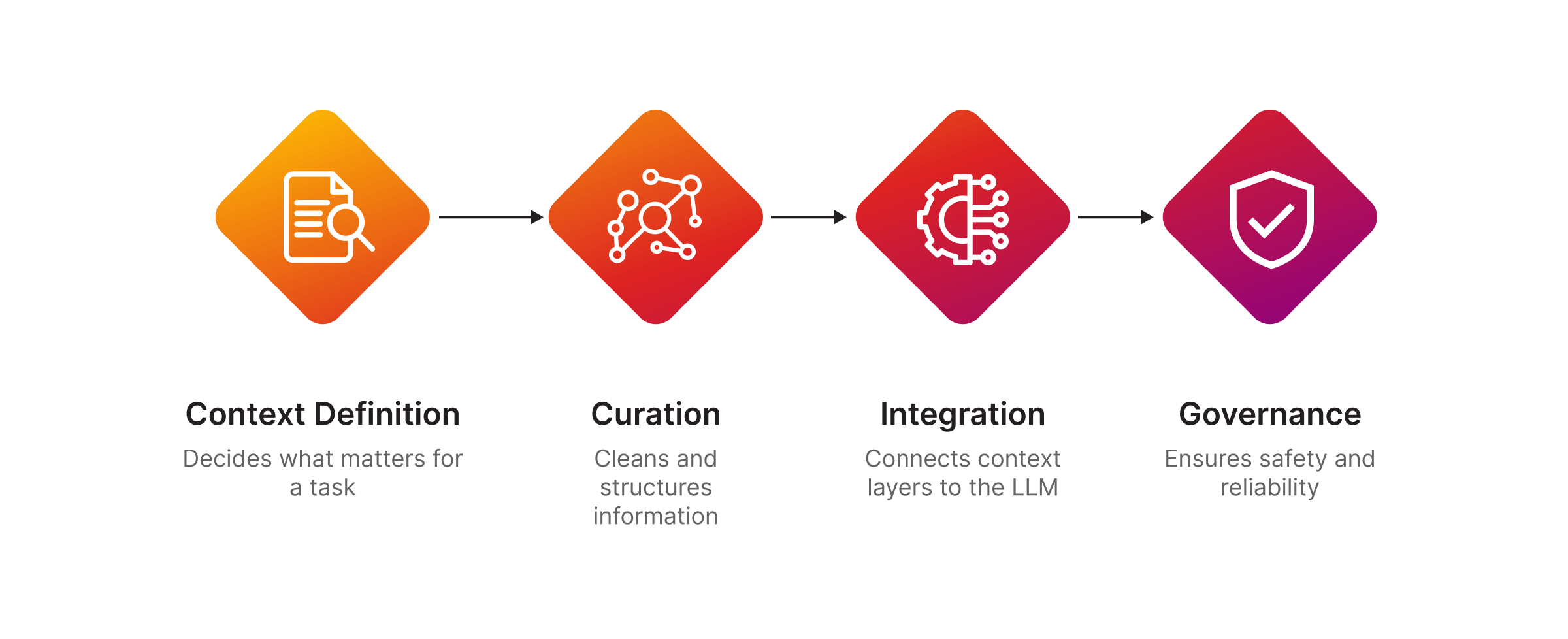
Context Engineering Components
1. Context Definition
Context definition is where you decide what actually matters for a task.
In practice, that means identifying:
- the data you need
- the user intent
- the business rules that apply
- any regulatory or compliance constraints
Without this step, teams tend to throw “all the data” at the model. That leads to noise, higher cost, and brittle behaviour.
A good context definition for a sales assistant, for example, will spell out that it needs:
- current opportunity details
- account history
- product and pricing eligibility
- approval thresholds for discounts
A fraud assistant will need a very different context definition, centred on transaction graphs, device histories, and case outcomes.
2. Curation
Curation is the work of cleaning, organising, and structuring information so that the model can actually use it.
This is where knowledge graphs and GraphRAG become practical tools rather than buzzwords.
In curation, you:
- resolve entities that appear differently across systems
- link customers, products, policies, events, and tickets
- normalise inconsistent fields
- attach business meaning to raw data
The context engineering master file describes this as cleaning, organising, and structuring information, often using knowledge graphs, so that it is ready for AI consumption.
Without curation, you end up with an LLM staring at messy, duplicated, or contradictory data. It will still answer. It just won’t know which version of reality to trust.
3. Integration
Integration is about connecting these curated context layers to the LLM system.
In practice this means combining:
- graph-based context
- vector indices over text
- live tools and APIs
- memory and task history
through APIs, pipelines, and context-fusion methods, so the model can dynamically use both structured and unstructured data during a task.
This is where retrieval strategies live. You decide:
- which store to query first
- how to join results from graphs and vectors
- how to trim and summarise context before it reaches the model
Effective integration is what stops the LLM from drowning in context windows while still giving it enough evidence to make reliable decisions.
4. Governance
Governance is the safety net and the brakes.
It covers:
- rules for data access and visibility
- validation and quality checks on retrieved context
- update policies so stale data does not quietly undermine answers
- controls over what the LLM can retrieve and reveal to which user
For enterprise apps, this is non-negotiable. Governance is where you encode who is allowed to see what, how PII is treated, what gets logged, and where human approval is required.
In other words, governance is how context engineering keeps powerful LLMs inside the bounds your organisation can actually accept.
Context Engineering is Cross-Functional by Design
It is easy to think of context engineering as something you only need for developer-facing tools or technical workflows. In reality, it becomes even more important when your end users sit in marketing, sales, HR, finance, or operations.
A few examples:
- A marketing assistant that suggests next-best campaigns needs to know which audiences are already saturated, which offers are allowed in each region, and which channels are currently under a freeze.
- A sales copilot drafting proposals needs to understand account history, current commercial terms, and which concessions require manager approval.
- An HR assistant answering benefits questions needs to apply different rules by country, role, and contract type without leaking sensitive data.
- A medical research helper needs to respect study protocols, inclusion and exclusion criteria, and regulatory boundaries when suggesting interpretations.
- A fraud-review assistant must see transaction graphs, device histories, and past cases together to avoid either blocking good customers or waving through risky ones.
All of these examples rely on the same underlying capability. The model must see the right slice of organisational knowledge, structured in a way that reflects how the business actually works, and scoped according to who is asking.
That is what context engineering delivers.
A Concrete Example: Context Engineering in Action
Imagine an internal support agent with access to an identity system, a ticketing tool, and a knowledge base.
A manager types:
Disable access for the contractor who left last week.
A naive agentic setup might expose all tools at once and let the LLM decide what to do. This is where mistakes multiply. The model may:
- disable the wrong identity because two names are similar
- pull HR details it should never see
- infer that a bulk action is needed
- skip the organisation’s change-control rules
A good context engineering setup changes the workflow:
- First, it resolves the entity, cross-checking identity records with contract end dates and manager ownership.
- Then it retrieves the relevant policy that governs off-boarding.
- It validates that the requester is allowed to initiate the action.
- Only then does it make the tool available for execution.
This does not require a superhuman model. It requires a system that controls context and tool availability based on structured understanding.
Why GraphRAG is a Practical Context Engineering Technique
Traditional RAG is effective when the question is mostly about topical relevance in unstructured text.
GraphRAG becomes valuable when:
- your data spans multiple silos
- relationships change the answer
- policies and constraints matter
- the task requires multi-hop reasoning
Microsoft Research introduced GraphRAG as a way to improve question answering over large private corpora by building and using graph structure during retrieval. The motivation aligns closely with real enterprise needs where raw text retrieval is not enough for complex questions.
From a developer’s perspective, the key benefit is not ideological.
It is operational.
GraphRAG helps you narrow the search space and present the model with context that is already organised around entities and relationships. That makes it easier for the model to stay grounded when you move from Q and A to decision-making agents.
How to Measure Context Engineering Success
Context engineering should be tested and measured like any other system component. Start simple. Build an evaluation set that includes both easy and tough questions.
Useful metrics include:
| Metrics | How to Measure |
|---|---|
| Answer Quality |
|
| Retrieval and Integration Quality |
|
| Agent Safety |
|
| Cost and Latency |
|
It’s important to measure these. If you don’t, you won’t be able to assess the success of the pipeline.
How Memgraph Fits into a Context Engineering Stack
Memgraph is a high-performance, in-memory graph database that serves as a real-time context engine for scalable AI applications.
In context engineering terms, that means it can serve as the structured layer that helps your LLM:
- resolve entities and relationships quickly
- retrieve policy-aware context
- support GraphRAG pipelines that combine structured and unstructured sources
- keep context updated as operational data changes
For teams new to graphs, you can join our JumpStart programme to quickly get started with your GraphRAG POC.
The Key Takeaway
Prompt engineering is still part of the job. But it lives inside the container that context engineering builds.
If you are building GraphRAG-powered chatbots or agentic workflows that support people in various enterprise function like marketing, sales, service, HR, finance, risk, or operations, context engineering is the practice that keeps your application accurate, safe, and cost-conscious. All while improving your productivity and freeing up your time for business-critical tasks.