
Graph Database vs Relational Database
Choosing the right type of database to store data in is a crucial decision that can impact the success of your personal or company project. Whether you need to decide between using a graph database or a relational database or want to learn about the differences between those two, you've come to the right place.
In the process of making the best database choice, developers are typically asking themselves several key questions: "Should I choose an open source over a commercial database? How easy is it to integrate the database with my application or manage and maintain the database? Or which database offers the best performance for my particular use case?"
To answer these questions, you first need to know what kind of data you are working with, what kind of queries you need to run, how much data you will be storing, how important performance is, and, after all, what your team's expertise is. This blog post will provide answers to those key questions along with discussing valuable examples to make your decision-making around graph database vs relational as easy as possible.
How is a graph database different from a relational database?
A graph database sees the world as we do! It is a type of database that stores data in the form of nodes connected with relationships.
Graph databases that are based on a labeled-property graph data model consist of four components:
- Nodes - the main entities in a graph. They are also sometimes referred to as vertices or points.
- Relationships - the connections between those entities. Sometimes they are referred to as edges or links.
- Labels - attributes that group similar nodes together.
- Properties - key/value pairs stored within nodes or relationships.
Nodes and relationships are fundamental components that are used. Labels and properties are often included because of the added functionalities they offer.
Graph databases mostly use Cypher query language since it is widely adopted, fully specified, and is an open query language for property graph databases. There are other graph query languages out there, but Cypher is the most popular one as it provides an intuitive way of working with property graphs.
Relational databases store data in tables consisting of rows and columns. Every row is a record, and every column is an attribute of that record. Relational databases are based on a relational data model that requires a predefined and carefully modeled set of tables. Multiple data tables can be related to each other using primary and foreign keys. Primary keys uniquely identify each row in a table, while foreign keys link rows in one table to rows in another table. Relational databases use Structured Query Language (SQL) to query, manage and manipulate data. Relational databases are widely used in applications such as e-commerce, banking, and inventory management systems.
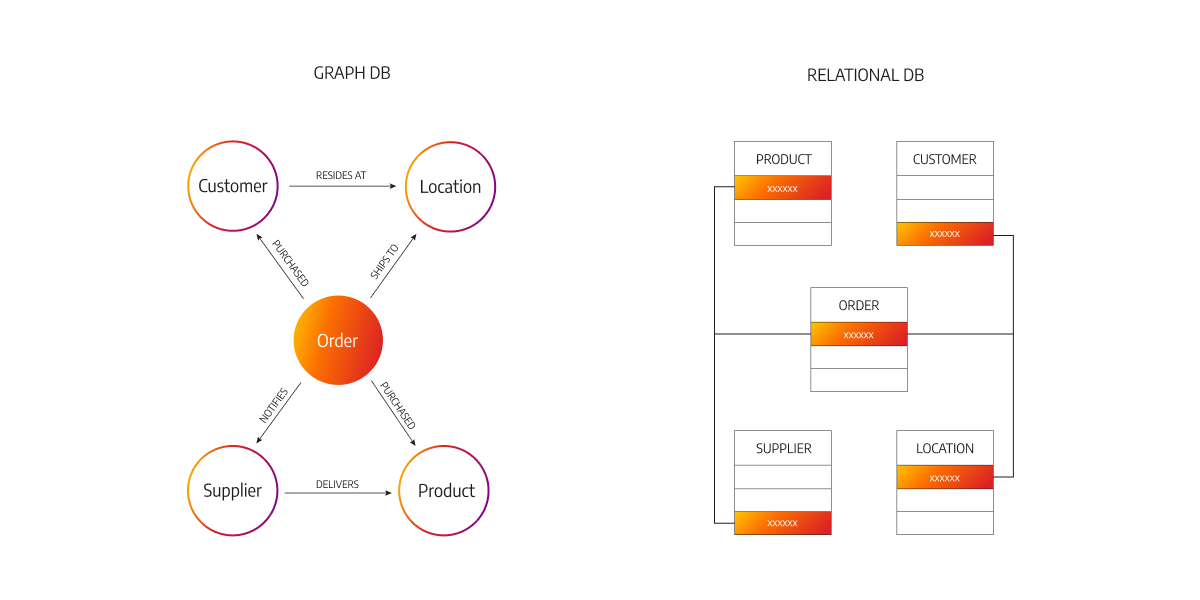
The image below shows the difference between the graph model and the relational model for the order management dataset.
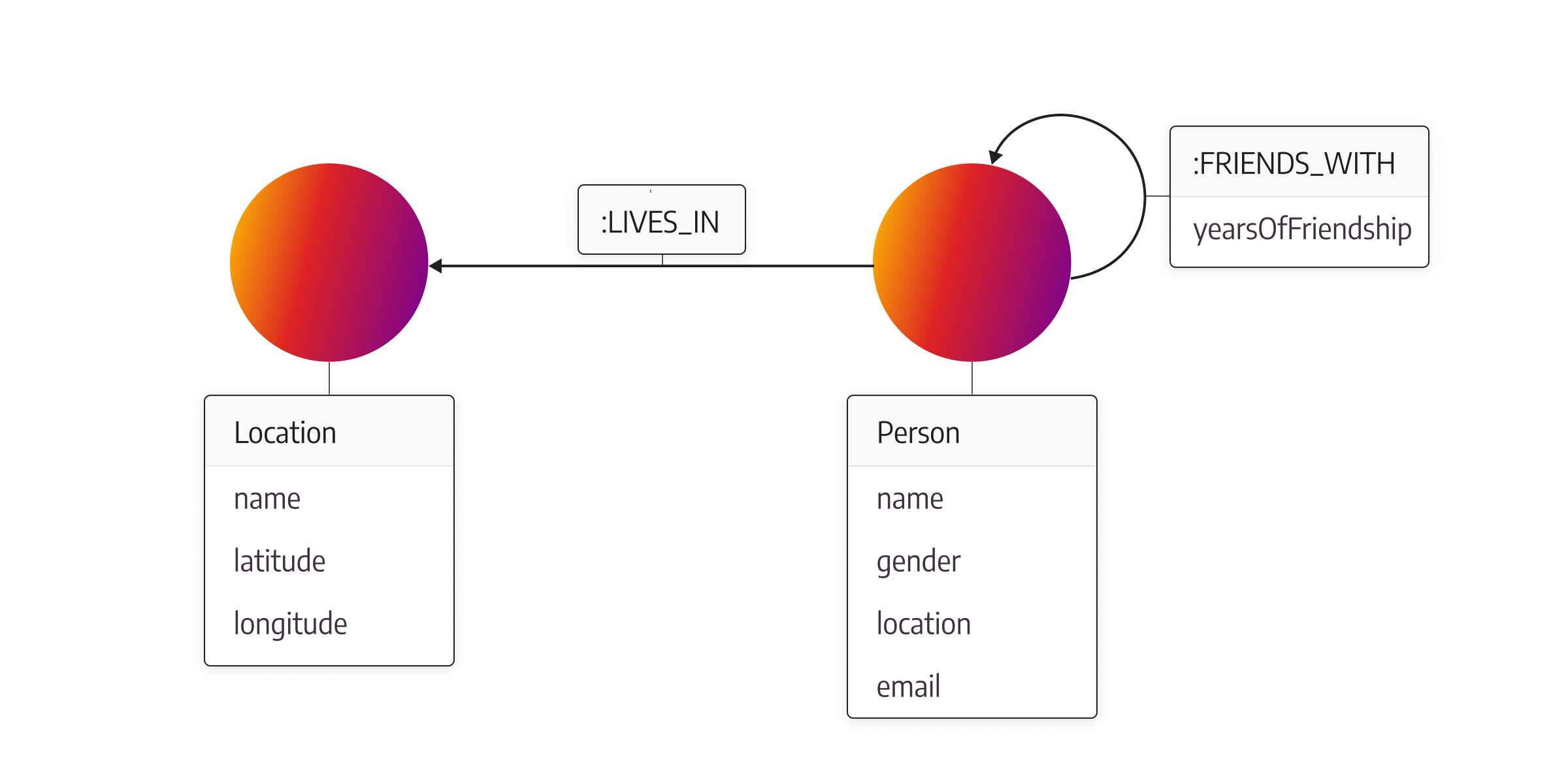
In the image below, there is another example, a social network graph data model, where the nodes represent people in different social groups and their connections. Every person is represented with a node that’s labeled as Person. These nodes contain the property name, gender, location, and email. The relationships between people in this network are of the type FRIENDS_WITH and contain a yearsOfFriendship property to specify the duration of the friendship connection. Each person is assigned a location through LIVES_IN relationships with nodes labeled Location.
Each person is connected to other people through friendships, and to model this relationship in a relational database, a table needs to be created. If there were different kinds of connections schema would have to be changed accordingly. A relational database isn’t suited for this specific use case because the focus isn’t on the data but on the relationships within it.
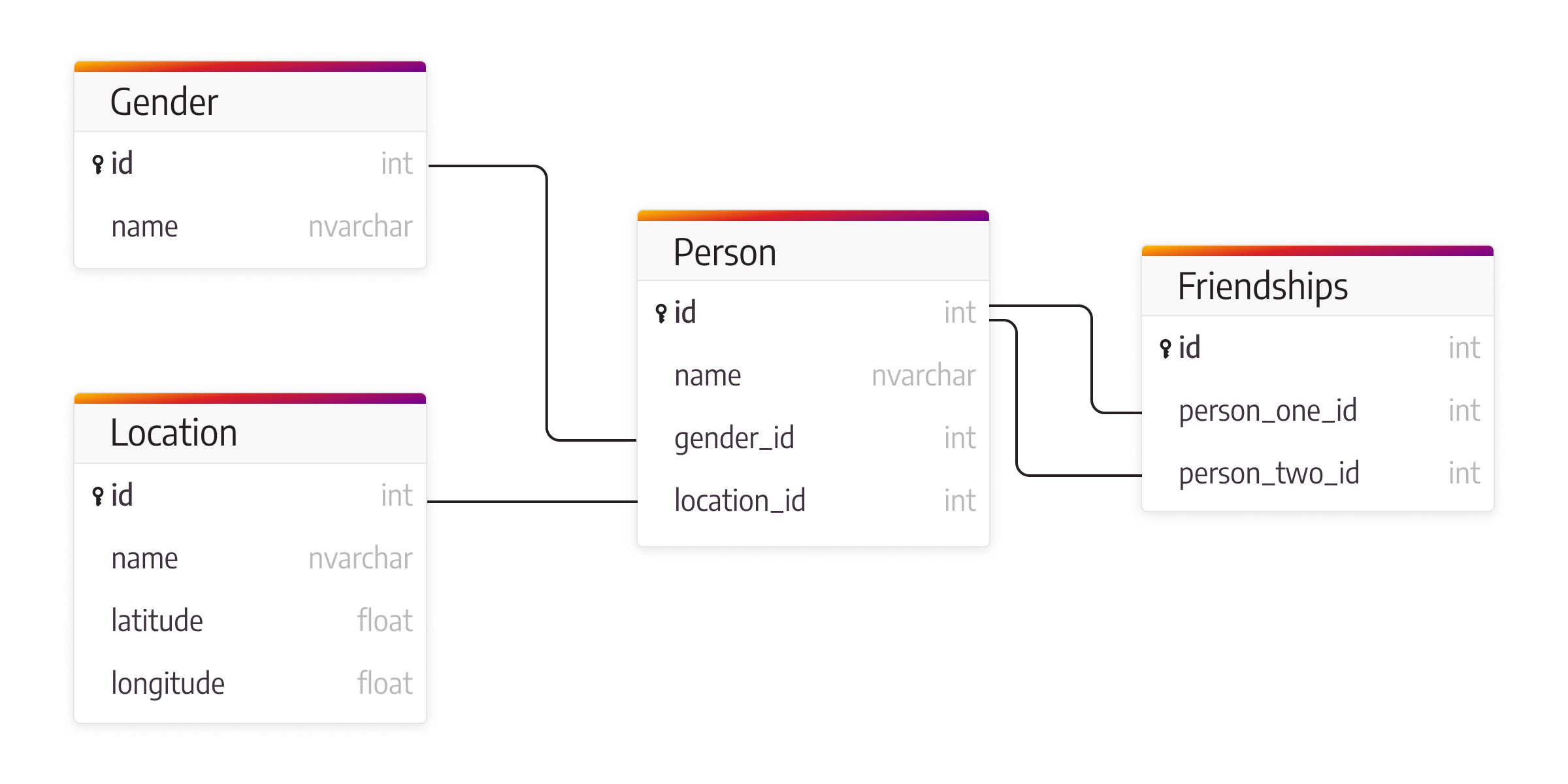
While this is a straightforward example, it concisely demonstrates the power and benefits of using a graph database. In relational databases, a new column must be added for each additional attribute, while with the flexible graph database schema, new properties can be added on the fly.
Cypher vs SQL query language
Cypher is a powerful and flexible query language specifically designed for working with graph databases. Its syntax and functionality make it well-suited for complex queries involving highly connected data - deep hierarchical relationships between data, such as parent-child relationships or many-to-many relationships between different tables. You can think of Cypher as mapping English language sentence structure to patterns in a graph. In most cases, the nouns are nodes of the graph, the verbs are the relationships in the graph, and the adjectives and adverbs are the properties.

SQL is a programming language used to manage and manipulate relational databases. It is used to create, modify, and query databases and their tables, as well as to insert, update, and delete data in the tables. It is a standard language used by most relational database management systems, including MySQL, Oracle, Microsoft SQL Server, PostgreSQL, and SQLite.
The difference between Cypher and SQL can be shown through an example dataset containing the genealogy of some ancient French kings around the 8th century AD from the MySQL Blog Archive. The easiest way to represent the dataset is with a graph:
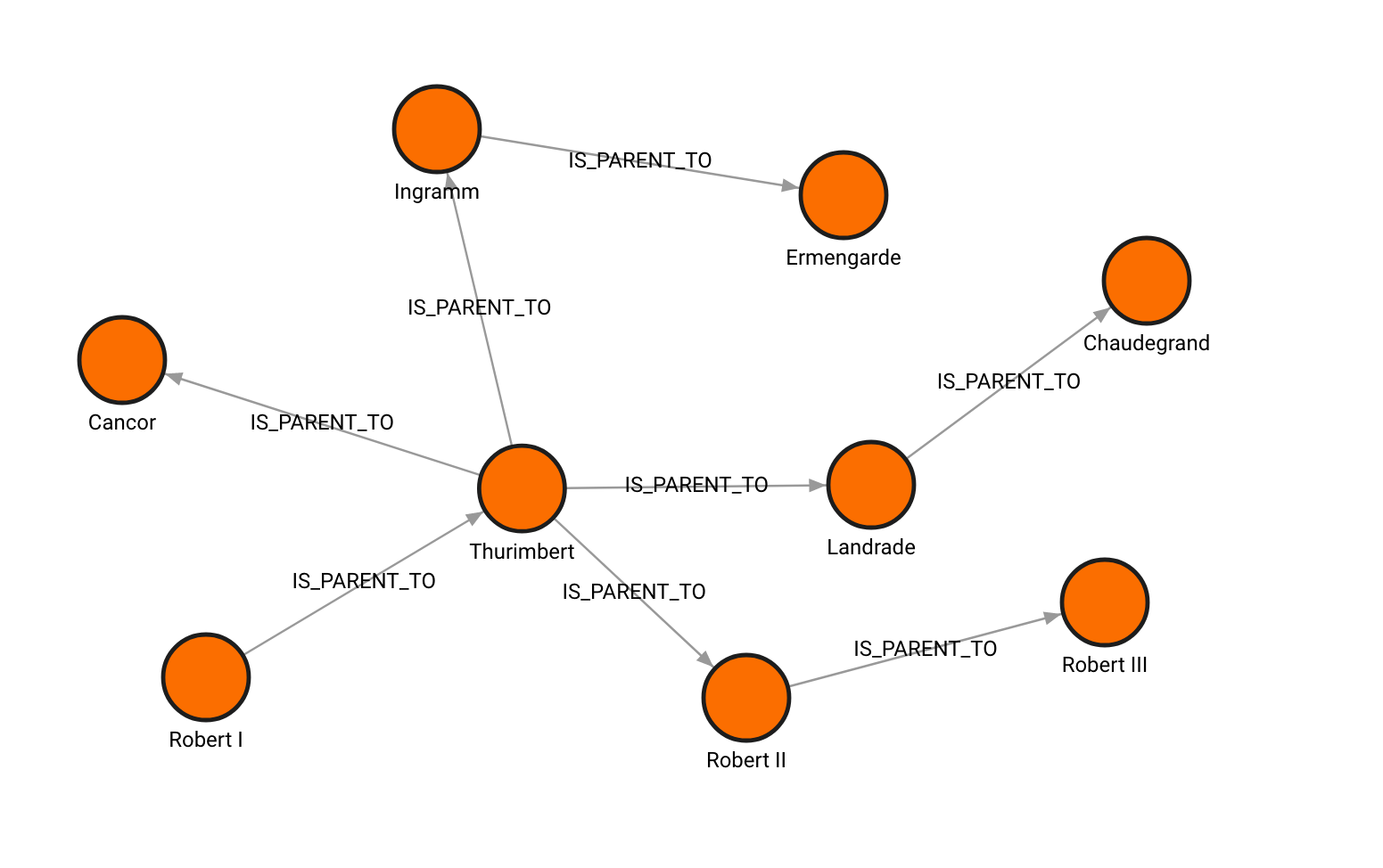
With breadth-first search and depth-first search, it is possible to obtain the descendants in a specific order. Here are the SQL and Cypher queries to find all descendants of Thurimbert:

To run the breadth-first search, that is, find all children, direct descendants first, grouped, use the following queries:

On the other hand, for the depth-first search, use the following queries:

The above dataset is naturally stored as hierarchical or graph data. The great thing about Cypher queries is that they tend to focus on the relationships between nodes in the graph, while SQL queries tend to focus on the columns and rows in tables. Also, path traversals such as breadth-first search and depth-first search are basic queries in Cypher. That’s why these kinds of queries are easier for developers to understand and write in Cypher. Besides that, on a larger scale of data, Cypher queries are more performant than SQL recursive calls for these kinds of use cases.
Overall, the main differences between Cypher and SQL stem from the different data modeling approaches and optimizations of the graph and relational databases. Cypher is designed to work with graph data and is optimized for queries that involve complex relationships. In contrast, SQL is designed to work with tabular data and is optimized for simpler queries. Compared to SQL, which can have a steep learning curve, Cypher is often easier for developers who are new to graph databases. And it provides an expressive syntax for working with graph data, allowing developers to create complex queries with fewer lines of code.
When to use a graph database?
There are always two sides to every story and graph databases aren’t a perfect solution for every problem. Of course, for a bunch of use cases, you should stick with relational databases or maybe search for alternatives other than graph databases.
To break it down for you, here are three simple questions you can ask yourself to decide if using a graph database has any benefits for your particular use case.
1. Is my data highly connected?
Graph solutions are focused on highly connected data with an intrinsic need for relationship analysis. In relational databases, complex data relationships arise when data from different tables is related or somehow interconnected. Because data is spread across multiple tables, querying it requires hopping from one table to another and joining it with slow and resource-intensive join operations. The complexity of join operations can increase exponentially as the number of tables increases and as the links between various tables are no longer neatly structured following a clearly set pattern. It is no longer sufficient to join just two or three tables: rather hop through more than seven tables to find the correct link between the data and gain valuable analytics. In that case, graph databases are the solution to go with.
If the connections within the data are not the primary focus and the data is transactional, then a graph database is probably not the best fit. Sometimes it’s just important to store data and complex analysis isn’t needed.
In the social network example, without the relationships between people stored, you get a sparsely connected graph. Yes, a number of simpler graphs would remain because of the connections between nodes Person and Location, but this degree of connectedness and the consistency of the data structure is better suited for a relational database.
2. Is retrieving the data more important to me than storing it?
Graph databases are optimized to retrieve data and they offer the power of graph analytics that can help discover hidden patterns in the data that were previously unseen with relational databases.
In the social network example, if the data is stored only for the sake of logging interactions without analyzing them later on, then a graph database isn’t particularly helpful. However, if there are numerous connections within the data being stored, then a graph might be worth considering. In the mentioned example, you can discover the most important or similar users, predict new connections, and group similar users into communities using PageRank, betweenness centrality, node2vec, or similar graph algorithms.
3. Does my data model change often?
Graph databases are best suited for data models that are inconsistent and demand frequent changes. Because graph databases are more about the data itself than the schema structure, they allow a degree of flexibility.
On the other hand, there are benefits to having a predefined and consistent table that’s easy to understand. Developers are comfortable and used to relational databases and that fact cannot be downplayed. For example, to store personal information such as names, dates of birth, and locations, without often creating new fields or changing data types, relational databases are the go-to solution.
A graph database could be useful if:
- Additional attributes will be added at some point
- Not all entities will have all the attributes in the table
- The attribute types are not strictly defined
To better understand the use cases best suited for graph databases, here are a couple of examples:
Insurance fraud detection
Graph databases help detect anomalies and make the information system more responsive. They allow for unexpected changes in the data structure and enable insurance companies to successfully expand their business as they tap into the insights provided by the recommendations engines (built on top of the data). A graph database is much better in this use case compared to a relational database because graphs perform faster with highly interconnected data. The graph model is flexible. Tight connections and patterns between entities can help design recommendation and fraud detection systems in insurance.
Network resource optimization
With a graph database, you can manage networks in the supply chain, chemical engineering, cloud computing, energy systems, and many more industries. Additionally, you can do quantitative analysis, and discover dependencies and critical points in your network so you can prevent obstructions and increase the network's efficiency. With relational databases, visualizing the topology takes around a third of the processing time, while in graph databases, data is automatically joined when it’s being stored, making sure graph traversing is performed in constant time.
Identity and access management
Graph databases have dynamic algorithms that analyze only a subset of the graph where changes happen and, in that way, avoid security crises. Besides that, graphs offer fast traversals with BFS or DFS hops due to index-free adjacency. Graphs represent relationships in a semantically rich way, allowing accurate views of access rights and simplifying their management, which is impossible with a hierarchical structure.
When not to use a graph database?
A graph database is only sometimes the perfect solution since it is not well-suited for traversing the whole graph often. While it’s possible to run such queries, other storage solutions may be more optimized for bulk scans. If the majority of the queries in the social network example included searches by property values over the entire network, then a graph database wouldn’t be the right fit.
Databases are often used to look up information stored in key/value pairs. For example, if the sole purpose of the database is storing the user’s personal information and retrieving it by name or ID, then refrain from using a graph. But if other entities were involved (visited locations for example), and a large number of connections is required to map them to users, then a graph database could bring performance benefits. If most queries return a single node via a simple identifier (key), then skip graph databases. If the entities in the model have very large attributes like BLOBs, CLOBs, and long texts — graph databases aren’t the best solution.
While those objects can be stored as nodes and linked to other nodes to utilize the power of traversing relationships, sometimes storing them directly with the entities they are connected to makes more sense.
Again, back to our favorite social network example, if each person had a long biography that needed to be included in the same database, a graph wouldn’t be the answer. However, if you needed to connect these biographies to other entities in the database (for example, people that are mentioned in them), then the strengths of a graph database would outweigh the limitations.
Wrap up
To conclude, both relational and graph databases are powerful tools. Graph databases handle fast-changing interconnected data well, while relational databases shine in managing structured data efficiently and effectively.
If you are still unsure if a graph database is the right choice for your project, drop us a message in our Discord community. We’ll be happy to address any doubts! Besides that, you can explore the most common graph use cases and maybe find the solution for your project on our site. If you are considering different graph database stores, check Memgraph’s latest benchmarks to see how it compares to the other graph solutions.